Die neue Custom-Operator-Erweiterung in RapidMiner beschäftigt mich weiter.
In den letzten Tagen habe ich zwei detaillierte Anleitungen in die RapidMiner-Community gestellt, um anderen die Entwicklung eigener Operatoren sowie die Arbeit mit der GeoProcessing-Extension zu vereinfachen:
The mesmerizing Custom Operators extension in RapidMiner is keeping me busy.
I put two detailed tutorials into the RapidMiner Community in order to make it easier for others to create their own operators and to start analyzing data with the GeoProcessing extension:
Als vor 1-2 Jahren die ostasiatischen Leihfahrrad-Anbieter mitteleuropäische Städte mit ihren Billigrädern zur Miete überfluteten, war die Preispolitik ein wichtiger Punkt in der Diskussion. Es war mehr oder weniger Konsens, daß es den Anbietern langfristig nicht um die wenigen Cent für die Kundenfahrten geht, sondern um die Bewegungsdaten der Kunden.
Jetzt sind E-Tretroller der letzte Schrei, in Wien stehen schon drei Anbieter. Sie müssen ihre Tretroller jeden Abend einsammeln und in der Früh rausbringen, sie zwischendurch aufladen, die Funktion prüfen und warten. Das ist angesichts der Kosten von Arbeit in Österreich schon ein gewagtes Geschäftsmodell. Die theoretische Bewertung der beiden US-Anbieter liegt laut Medien im Milliarden-Bereich. Hierzu gibt es wieder die Annahme, daß zukünftige Einnahmen nicht nur durch die (ziemlich günstigen) Kundenfahrten, sondern durch Auswertung und Verkauf der Bewegungsdaten generiert werden können.
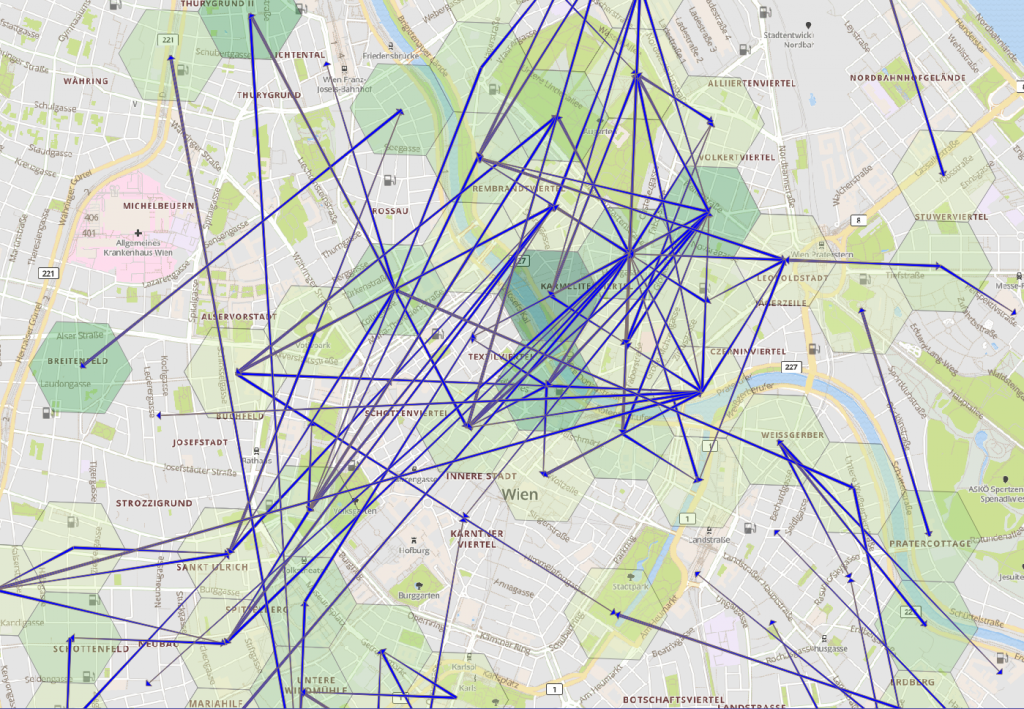
Hexagonale Felder, aus denen viele SCO2T-Fahrten ausgingen, Ziele der Fahrten. Anzahl der Fahrten durch die Dicke der Pfeile angedeutet.
Denken wir dieses Geschäftsmodell mal für Europa durch. In der EU gelten strenge Datenschutz-Vorschriften, es ist also zumindest legal nicht möglich, Daten wie „XY ist am 1.12.2018 von A nach B gefahren“ zu verkaufen. Sehr wohl kann man aber Daten aggregieren und Dinge auswerten wie „Aus dem Bereich von Alt-Erlaa in den Bereich der UNO-City fahren am Tag durchschnittlich 7 Menschen, 4 davon am Vormittag, 2 am Nachmittag und 1 am Abend“. Nur, wer fragt solche Informationen nach, und wie viel ist er/sie bereit, dafür zu zahlen? Die Stadt Wien, VerkehrsplanerInnen, vielleicht Firmen, die autonomes Fahren entwickeln, andere Verkehrsdienstleister. Nur wird diese Art von Information schon entweder selbst erhoben (die Wiener Linien können das z. B. sicherlich zählen), oder seit Jahren etwa von Mobilfunkfirmen angeboten.
Bei SCO2T haben wir in mehr als vier Jahren, mit vielen tausend Fahrten pro Monat, mit einer großen Präsenz in Fachkreisen und bei Konferenzen, keine einzige Anfrage in diese Richtung bekommen. Das deutet für mich eher darauf hin, daß dieser Markt für aggregierte Bewegungsdaten (noch) nicht existiert, zumindest nicht in Wien.
Neben dem Verkauf der Daten kann man sie natürlich auch intern analysieren, damit Prozesse optimieren und die Dienstleistung für die Kunden verbessern. Z. B. können wir die Scooter nach einer Servicefahrt dort abstellen, wo die Wahrscheinlichkeit einer neuen Miete am höchsten ist. Für diese Analyse sind die Daten von vergangenen Fahrten ohne Kundenbezug notwendig. (SCO2T bezieht grundsätzlich keine personenbezogenen Daten von Kunden in solche Analysen ein — es ist einfach nicht notwendig.)
Meine Schlußfolgerung: Ich als Data Scientist mit GIS-Erfahrung und direktem Zugang zu entsprechenden Bewegungsdaten sehe keinen großen legalen Markt für den Verkauf dieser Daten.
Natürlich könnten Anbieter auf illegale (oder zumindest im Kleingedruckten versteckte und unmoralische) Ideen kommen. Z. B.: Kunde A ist schon öfter ins Donauzentrum gefahren und ist wieder auf dem Weg dorthin. Voraussichtliche Ankunft: 13:30. Wenn man diese Information an Google weitergeben kann, könnte ich mir vorstellen, daß dafür einige Cent gezahlt werden — schließlich kann der Person dann zur richtigen Zeit ortsbezogene Werbung gezeigt werden. Diese Geschäftsmodelle existieren in den USA, und werden als Zukunft der Werbung angesehen — ich sehe aber nicht, wie sie mit der DSGVO vereinbar wären, außer mit expliziter Zustimmung der Kunden. Und selbst wenn — Milliarden wird man damit auch nicht verdienen (nur Google).
Ich habe früher beschrieben, wie geographische Joins und Filter in RapidMiner mit Hilfe des Cartesian-Product-Operators umgesetzt werden. Dieser Ansatz ist relativ einfach nachvollziehbar und funktioniert mit kleinen Datenmengen ganz gut.
Leider wird bei einem Cartesian Join jede Zeile der beiden hineingehenden Datensätze miteinander kombiniert. Das Ergebnis des kartesischen Produkts hat dann so viele Zeilen wie das Produkt der beiden Datensatzlängen. Natürlich wird da viel Speicher verwendet, und die Schleife mit den gewünschten Berechnungen läuft länger.
Für größere Datenmengen mit jeweils Hunderten oder Tausenden von Zeilen gibt es einen besseren Ansatz. Der Script-Operator kann auch zwei ExampleSets verarbeiten. Mit einem etwas komplexeren Skript kann der Prozess in einer verschachtelten Schleife beliebige Join-Kriterien anwenden, ohne den Speicher mit einem temporären kartesischen Produkt zu belasten.
In diesem Beispielprozess hole ich von Open Data Wien eine Liste von über 28.000 Straßenabschnitten in Wien (als Linien) sowie die 23 Wiener Bezirke (als Flächen). Die Aufgabe ist, für jeden Bezirk die Straßen zu bestimmen, die in ihm liegen. Dafür wird die GeoScript-Funktion contains() verwendet.
Bei der Cartesian-Join-Methode werden für jede Zeile zwei als String gespeicherte Geo-Objekte konvertiert. Dies ist aufwändig, aber kaum zu vermeiden. Mit der verbesserten Methode ist es einfach, ein Array von konvertierten Geo-Objekten zu erstellen und indexbasiert abzufragen.
Das Ergebnis ist ein Prozess, der mit relativ geringen Speicher-Anforderungen und einer akzeptablen Geschwindigkeit auch größere Datenmengen verknüpfen kann.
Der Nachteil ist ein etwas komplexeres Skript, das jedoch nach der ersten Entwicklung leicht an neue Anforderungen angepaßt werden kann.
Der größere Aufwand lohnt sich aber auf jeden Fall. Der Beispielprozess ordnet auf meinem Rechner die 28.309 Straßen den 23 Bezirken in ca. 14 Sekunden zu. Ein versuchsweise erstellter alternativer Prozess, der mit Cartesian Join arbeitet, läuft über 20 Minuten, also fast 90 mal langsamer, und braucht dabei natürlich deutlich mehr Speicher.
Das Skript erstellt ein komplett neues ExampleSet, das alle Attribute aus den beiden hereinkommenden ExampleSets übernimmt (doppelte Attributnamen sollten vorher korrigiert werden). Das Ergebnis enthält nur die Datensätze, auf die die Bedingung zutrifft, es ist kein nachgeschalteter Filter notwendig.
Um das Skript möglichst wiederverwendbar/flexibel zu machen, werden alle prozess-spezifischen Teile am Anfang als Variablen konfiguriert. Das sind einerseits die Namen der beteiligten Attribute, andererseits aber auch die Join-Funktion. Da Groovy sogenannte Closures (Funktionsvariablen) anbietet, können wir am Anfang des Skripts die verwendete Funktion eingeben – die hier konfigurierte Funktion wird später im Join verwendet.
Konkret sieht die Definition so aus:
def joinFunc = { a1, a2 -> a1.contains(a2) }
Das bedeutet: eine Funktionsvariable namens joinFunc mit den Parametern a1 und a2 erstellen. Hinter dem -> erscheint der Inhalt der Funktion, in diesem Fall der Aufruf a1.contains(a2). Der Rückgabewert sollte ein Boolean sein; beim Rückgabewert True werden die beteiligten Zeilen ins Ergebnis ausgegeben. Der fixe Teil des Skripts ruft dann irgendwo in der Schleife die Funktion mit joinFunc(a1, a2) auf.
Diese Konstruktion hilft uns, das Skript einfacher wiederzuverwenden: Sollten wir einmal statt contains() etwa intersects() benötigen, braucht nur der Konfigurationsblock geändert zu werden. Wir müssen nicht mehr nach dem Funktionsaufruf irgendwo in den Tiefen des Skripts zu suchen.
Earlier I described geographic joins and filters in RapidMiner. The processes used the Cartesian Product operator. This approach is quite simple and easy to understand, and it works well with smaller data sets.
Cartesian Join combines each row of the incoming tables. The result has as many rows as the number of rows of both data sets multiplied together. This uses a lot of memory and the loop that calculates the results takes longer.
There‘s a better approach for larger data sets with hundreds or thousands of rows. The Execute Script operator can work with two incoming ExampleSets. A slightly more complex script can use nested loops to apply almost arbitrary join criteria on the data, without filling the memory with the cartesian product.
This example process fetches over 28,000 street segments as lines and 23 districts of Vienna as polygons from the Vienna Open Data server. The task is finding the streets inside each district. So this is a join based on the GeoScript function contains().
The Cartesian Join needs to convert two strings to Geometry objects in each line of the combined data set. This is slow and hard to avoid. The improved method makes it easy to create an array of converted Geometry objects and use them for further lookups.
The resulting process uses less memory and has an acceptable runtime even with large inputs. This comes at the cost of a more complex script; however, it should be easy to change the script for future requirements.
The effort is really worth it. On my computer the example process joins 28,309 streets with 23 districts in about 14 seconds. A variant of the process that uses Cartesian Join runs for over 20 minutes (about 90 times slower) and uses a lot more memory.
The script creates a new ExampleSet that combines all attributes of both incoming ExampleSets. (If you have duplicate attribute names, rename them before sending the data to the script.) The result contains only records that match the condition, no additional filtering is necessary.
In order to make the script as reusable as possible, all process specific parts are configured at the top in variables. There are variables for the join attributes‘ names and also for the join function. Groovy offers so-called Closures (function variables), so we can specify the function to use in the configuration block. The configured function will be used for joining later in the loop.
This is how the definition looks like:
def joinFunc = { a1, a2 -> a1.contains(a2) }
Translated: create a function variable called joinFunc created with parameters a1 and a2. The body of the function is specified after ->, in this case a1.contains(a2). The return value of the function should be a Boolean – if the value is True, the current rows will be put into the result example set.
The fixed part of the script calls this function using joinFunc(a1, a2) later in the loop.
With this construction we can reuse the script easily: If we need intersects() instead of contains() at some point in the future, we just change it in the script configuration, without having to analyze and change the code below.
Nach der Artikelserie über GIS in RapidMiner Studio (1, 2, 3, 4) geht es nun darum, wie die erhaltenen Ergebnisse visualisiert werden können. In Studio sind die Möglichkeiten dafür ja ziemlich eingeschränkt: Punkt-Daten können noch halbwegs als Scatterplots angezeigt werden, aber für Linien und Flächen gibt es keine guten Methoden.
RapidMiner Server bietet aber mit den Webapps die Möglichkeit einer flexiblen Visualisierung durch die Einbindung von JavaScript.
Einbindung von GeoTools
Für die nachfolgende Vorgehensweise ist es nicht notwendig, den Server ähnlich wie Studio mit Geo-Libraries auszustatten. Wenn man jedoch die gleichen GIS-Funktionen wie in Studio verwenden will, kann es sinnvoll sein.
Ausgehend vom eingerichteten geoscript-Verzeichnis wie im ersten Teil der Anleitung werden die Jar-Bibliotheken aus diesem Verzeichnis in die EAR-Datei des Servers kopiert. Man braucht dazu ein Zip-Werkzeug, ich habe den Midnight Commander verwendet.
RapidMiner Server beenden
rapidminer-server/standalone/deployments/rapidminer-server-X.Y.Z.ear zur Sicherheit anderswo hinkopieren
Aus dem lib/-Verzeichnis die alte groovy-X.jar löschen und die neue aus der Studio-Installation hineinkopieren
Alle Jar-Dateien aus dem geoscript-Ordner der Studio-Installation auch in lib/ kopieren. Wenn eine Datei schon vorhanden ist, muß sie nicht überschrieben werden.
RapidMiner Server starten.
Danach sollten alle Prozesse mit GIS-Verarbeitung aus Studio auch am Server funktionieren.
Visualisierung in Webapps
Meine Wahl fiel auf die Leaflet-Library, da sie Open Source und gut dokumentiert ist. Da wir in RapidMiner keinen eigenen GIS-Datentyp haben und die bisherigen Prozesse die Geodaten als WKT (Well Known Text) verarbeiten, brauchen wir noch die Mapbox-Omnivore-Library. Diese konvertiert WKT-Daten in GeoJSON, das bevorzugte Format von Leaflet.
Vor der Erstellung des Webapps bauen wir einen Prozess in Studio, der die gewünschten Daten ausgibt. Ein Beispielprozess könnte vom Wiener Open-Data-Server die Bezirksgrenzen als CSV und Bevölkerungsstatistiken holen. Die Bezirke werden über ein gemeinsames Feld (NUTS-Id) verknüpft. Der Output des Prozesses ist eine Tabelle mit den Geodaten des Bezirks, ihrer Fläche, der Gesamtbevölkerung und der Bevölkerungsdichte. Für die Bevölkerungsdichte errechnen wir mit Generate Attributes die Anzahl der Personen pro Quadratkilometer und klassifizieren sie, indem wir verschiedenen Wertbereichen HTML-Farben in der #AABBCC-Notation zuweisen. Hier ist die eigene Kreativität gefragt.
Der Prozess wird auf den Server gelegt. Unter Processes/Services legen wir eine neue Eintragung an und nennen sie z. B. ViennaDistrictPopDensitySvc. Wir wählen als Datenquelle den vorhin angelegten Prozess und als Output Format JSON. Es ist sinnvoll, dieses Webservice als anonym/öffentlich aufzusetzen, um zusätzliche Paßworteingaben zu vermeiden.
In der neuen Webapplikation erzeugen wir eine Komponente vom Typ Text, und schalten „Use graphical editor“ ab. Danach geben wir den HTML- und JavaScript-Code ein.
Dieser Teil holt die Leaflet- und Omnivore-Komponenten und erzeugt ein Objekt, in das die Karte eingefügt werden kann. Im CSS wird die Höhe in Pixeln angegeben (z. B. 650px).
Danach starten wir mit <script language="JavaScript"> einen JavaScript-Block, der am Ende mit </script> geschlossen wird.
Hier erzeugen wir das Kartenobjekt mit einer OpenStreetMap-Hintergrundkarte. Die Initialisierungsparameter sind Längen- und Breitengrad der anfänglichen Position der Karte, die Zahl dahinter (11 in diesem Beispiel) die Zoom-Stufe.
Es gibt viele Tile-Server, man sollte die Nutzungsbedingungen prüfen und die Herkunftsangabe (attribution) entsprechend anpassen.
Daten des RapidMiner-Prozesses holen
var Httpreq = new XMLHttpRequest();
Httpreq.open("GET","/api/rest/public/process/ViennaDistrictPopDensitySvc?",false);
Httpreq.send(null);
var mapdata = JSON.parse(Httpreq.responseText);
Dieser Block holt vom lokalen (oder auch einem beliebigen anderen) RapidMiner Server die Daten des Prozesses im JSON-Format und legt sie im mapdata-Objekt ab. Die URL des Webservice kann hier angepaßt werden.
Anzeige der Geo-Objekte
for (i = 0; i < mapdata.length; i++) {
var district = omnivore.wkt.parse(mapdata[i].SHAPE);
district.addTo(map)
.bindPopup(mapdata[i].NAME + "
Population density: " + mapdata[i].POP_DENSITY)
.setStyle({color: mapdata[i].densityColor, weight: 2, fillOpacity: 0.3});
}
Hier verarbeiten wir die Ergebnisse des Prozesses in einer Schleife. Aus jeder Zeile wird die Form des Bezirks (Attribut SHAPE in den Beispieldaten) mit Hilfe von Omnivore konvertiert, und als neues Objekt zur Karte hinzugefügt. Mit .setStyle(...) ordnen wir die im Prozess erzeugte Farbabstufung (im Beispiel das densityColor-Attribut) zu. Als zusätzliche Information erzeugen wir mit .bindPopup(...) noch ein Popup-Fenster, das beim Klick auf einen Bezirk angezeigt wird und zusätzliche Informationen enthält.
Linien-Daten werden ganz ähnlich angezeigt und verarbeitet. Bei Punkt-Daten können verschiedene Marker definiert werden, bei Leaflet gibt es die Anleitung dazu.
Damit ist das Ziel erreicht: RapidMiner Server zeigt eine Karte an, deren Daten (Punkte, Linien oder Flächen) in einen RapidMiner-Prozess verarbeitet wurden.
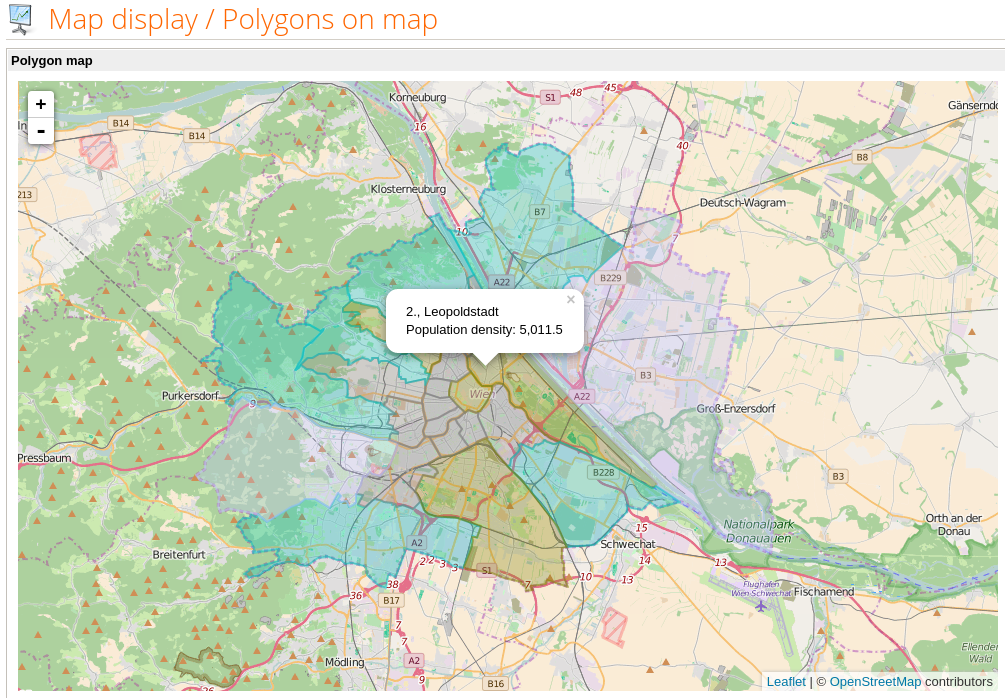
Bevölkerungsdichte pro Bezirk in Wien (Daten: Open Data Wien)
After the series of blog posts about GIS in RapidMiner Studio (1, 2, 3, 4) we’d probably like to visualize our results. The mechanisms in Studio are quite limited: we can create scatter plots from point data but there is no good method for displaying lines and areas.
However, RapidMiner Server offers webapps and powerful visualization using JavaScript.
Using GeoScript in processes
For displaying geographic data it’s not necessary to set up the server with the GeoScript libraries. However, if you want to execute the GIS processes like in studio, it can be a good idea to do so.
Start with the geoscript directory set up in the first part. You’ll need a Zip utility; I used Midnight Commander.
Stop RapidMiner Server
Make a backup copy of rapidminer-server/standalone/deployments/rapidminer-server-X.Y.Z.ear somewhere else
Delete the old groovy-X.jar from the lib/ directory and put in the new one from the Studio installation
Copy all jar files from the geoscript directory of the Studio installation to lib/. Existing files don’t need to be overwritten.
Start RapidMiner Server.
After this process, all your Studio GIS processes should work in the Server.
Map display in webapps
I chose the Leaflet library, as it is open source and well documented. There is no special GIS data type in RapidMiner and the processes in the tutorials used WKT (Well Known Text) until now, so we’ll also need the Mapbox Omnivore library. This converts WKT data to GeoJSON which Leaflet prefers.
Before starting with the web app, we need to build a process in Studio for creating the data. An example process could use the district boundaries as CSV and the population statistics from the Vienna Open Data server. It joins the districts using a common attribute (NUTS id). The output of the process is a table with the district boundaries, their area, the total population and the population density. We also use Generate Attributes to classify the population density with HTML colors (#AABBCC notation). You can get creative here and use the entire functionality of RapidMiner.
The process is saved on the server. We create a new entry in Processes/Services and call it for example ViennaDistrictPopDensitySvc. The data source is the process created before, the output format is JSON. It is a good idea to set up this web service for public anonymous access.
In a new web app we create a Text component and uncheck the „Use graphical editor“ checkbox to enter HTML and JavaScript code.
This part fetches the Leaflet and Omnivore components and creates a DIV object for the map. We specify the map height in pixels in the CSS block (e. g. 650px).
Then a JavaScript block is started with <script language="JavaScript">. Don’t forget to close the block with </script> at the end.
This creates a map object with an OpenStreetMap background layer. The initialization parameters are latitude and longitude of the initial position, and the zoom level (11 in this example).
There are many tile servers available. Be sure to check the terms of usage and update the attribution appropriately.
Getting data from the RapidMiner process
var Httpreq = new XMLHttpRequest();
Httpreq.open("GET","/api/rest/public/process/ViennaDistrictPopDensitySvc?",false);
Httpreq.send(null);
var mapdata = JSON.parse(Httpreq.responseText);
This part fetches the data in JSON format from the local RapidMiner Server and stores them in the mapdata variable. To refer to another web service, change the URL.
Displaying the objects on the map
for (i = 0; i < mapdata.length; i++) {
var district = omnivore.wkt.parse(mapdata[i].SHAPE);
district.addTo(map)
.bindPopup(mapdata[i].NAME + "
Population density: " + mapdata[i].POP_DENSITY)
.setStyle({color: mapdata[i].densityColor, weight: 2, fillOpacity: 0.3});
}
Here, a loop processes the process results. The Omnivore function converts the district area (SHAPE attribute in the example data) to a new object on the map. We assign the color calculated in the process with .setStyle(...) (densityColor attribute in this example). We also create a popup window with additional information using .bindPopup(...). It will be displayed when the user clicks a district.
Displaying line data is very similar. For displaying point data, you can use different markers. This is described by a Leaflet tutorial.
So we reached our goal: RapidMiner Server displays a map with data (points, lines or areas or even a combination) coming from a RapidMiner process.
Population density by district in Vienna (Data: Open Data Vienna)
In diesem vierten Teil geht es um die Filterung von Datensätzen und die Verbindung mehrerer Datensätze anhand geographischer Kriterien. (Um die Beispiele nachzuvollziehen, muß RapidMiner wie in der Einführung beschrieben um die GeoScript-Libraries ergänzt werden.)
Da kein eingebauter Join-Operator für geographische Kriterien existiert, bauen wir diese Operation nach, indem wir jedes Element der beiden Datensätze miteinander vergleichen und das Ergebnis dann filtern. Der Vergleich wird mit geographischen Operationen durchgeführt.
In den bisherigen Beispielen wurde mit Hilfe des Cartesian-Product-Operators jede Kombination der Datensätze gebildet. Die andere Möglichkeit ist, in einer Schleife alle Elemente eines Datensatzes mit denen des anderen zu vergleichen.
(Dies ist wieder ein Bereich, in dem PostGIS mit geographischen Indizes in der Datenbank eine wesentliche Beschleunigung bietet, die bei wirklich großen Datenmengen auch noch gut funktioniert.)
Einige Funktionen, die uns für die Verbindung von Datensätzen zur Verfügung stehen:
distance: Diese Funktion haben wir bereits kennengelernt. Wenn wir die Distanzen aller Kombinationen bestimmt haben, können wir das Ergebnis filtern, um z. B. jene herauszufiltern, deren Distanz einen bestimmten Wert nicht überschreitet.
intersects: Liefert true, wenn die Objekte sich an mindestens einem Punkt überschneiden.
intersection: Erzeugt die Überschneidung der Objekte als neues geometrisches Objekt. Der Typ des überschneidenden Bereichs orientiert sich an den verglichenen Objekten: Z. B. ist die Überschneidung einer Fläche mit einer Linie wieder eine Linie. Wir können mit dem Ergebnis natürlich weiterarbeiten und z. B. die Fläche oder andere Kennzahlen bestimmen und darauf filtern.
contains: A.contains(B) liefert true, wenn das Objekt A das Objekt B vollständig enthält, also kein Teil von B außerhalb von A liegt.
Bei intersects und intersection ist die Richtung des Aufrufs egal (A.intersects(B) ergibt das gleiche wie B.intersects(A)). Bei contains jedoch nicht: Eine Fläche A kann einen Punkt B enthalten, was im umgekehrten Fall nicht gilt.
Eine häufig verwendete geographische Operation ist das Buffering, das mit der buffer-Funktion realisiert wird. Hierbei wird um das ursprüngliche Objekt (Punkt, Linie, Fläche) eine Fläche erzeugt, deren Grenze die im Funktionsaufruf angegebene Distanz zum Objekt hat. Das Ergebnis ist somit immer eine Fläche. Damit können wir verschiedene Dinge wie Einzugsgebiete von Geschäften, die Reichweite von Funkantennen oder die tatsächliche Fläche einer als Linie mit Breitenangabe angegebenen Straße berechnen. Mit der Berechnung des Buffers werden auch häufig Distanz-Vergleiche mit Hilfe von contains oder intersects durchgeführt.
Die Vorgehensweise in RapidMiner ist diese: zuerst werden in einem Execute-Script-Operator mit Groovy/GeoScript die benötigten Ergebnisse ermittelt (z. B. contains: true/false) und danach die Ergebnismenge mit Filter Examples gefiltert, sodaß nur die Objekte übrigbleiben, auf die das gewünschte Kriterium zutrifft (z. B. contains = true oder distance < 10).
Der Beispielprozess existiert in zwei Varianten: einmal mit Cartesian Product und einmal mit Loop Examples. Die erste Variante ist deutlich schneller, braucht jedoch sehr viel Speicher, weil sie riesige Tabellen anlegen muß. Die zweite Variante braucht viel länger, aber der Speicherverbrauch ist geringer, da keine „multiplizierten“ Datensätze erzeugt werden.
Für manche Operationen wie intersects oder contains ist die Projektion unerheblich (solange beide Geometrien im gleichen Koordinatensystem angegeben sind). Für buffer müssen wir aber eine Ausdehnung angeben, somit ist es wieder zweckmäßig, mit einer Meter-basierten Projektion zu arbeiten. Deswegen transformieren die Beispielprozesse alle Datensätze in die für Österreich geeignete Projektion EPSG:3416.
Drei Datensätze werden vom Wiener Open-Data-Server geholt: Wasserflüsse (Linien), Brücken (Flächen) und Spielplätze (Punkte). Dann sucht der Prozess mit intersects und intersection die Bereiche, in denen die Brücke über Wasser führt. Mit buffer wird der Bereich um die Wasserflüsse markiert, in dem mit contains nach Spielplätzen gesucht wird. Das Ergebnis ist dann eine Liste von Spielplätzen, die nahe an einem Bach oder Fluß liegen.
Damit ist diese Serie über GIS in RapidMiner vorerst abgeschlossen. Die besprochenen Methoden decken schon eine große Anzahl von Aufgaben ab, und mit etwas Kreativität ist noch viel mehr möglich. Ich werde sicherlich noch Anwendungen und Lösungen finden und darüber auch hier berichten. Wenn etwas unklar sein sollte, beantworte ich gerne Fragen: hier in den Kommentaren, im RapidMiner-Forum, oder auch direkt. Ich wünsche viel Erfolg!
GIS in RapidMiner (4) – Geographic Filter and Joins
The fourth part of this series is about filtering and joining example sets on geographic criteria. (RapidMiner needs to be extended with the GeoScript libraries as described in the Introduction for the examples to work.)
There is no built-in Join operator with support for geographic functions. So we reproduce this functionality by comparing each element of both example sets and filter the result. Geographic functions are used for the comparison.
In the examples until now, we used the Cartesian Product operator for building an example set with each combination of examples. The other way is a Loop over each element of example set 1 that compares the one example of the loop with all elements of example set 2.
(This is also an area where PostGIS shines with geographic indexes in the database that improve processing times by a huge factor, even in the case of huge tables.)
Some geographic functions usable for joining or connecting example sets:
distance: We already saw this. After calculating the distance of all combinations, we can filter the result set to only contain those within a certain distance.
intersects: Returns true if the objects have at least one point in common.
intersection: Creates a new geometry with the common parts of both objects. The type of the result depends on the compared objects: e. g. the intersection of an area and a line is again a line. The resulting geometry can be processed further, for example by calculating its area or other measures and filtering on those.
contains: A.contains(B) returns true if object A fully contains B, in other words, no part of B is outside of A.
The order of the objects is not relevant when using intersects and intersection: A.intersects(B) has the same result as B.intersects(A). This is not true for contains: An area A can contain point B but this is not true for the opposite.
Buffering is a popular geographic operation, available in the buffer function. Buffering creates an area around the original object (point, line, area) with a border in a distance specified in the function call. The result is always an area. We can calculate different things with buffering: the service area of shops, the coverage of wireless antennas or the actual area of a street that is specified as a line but has a width attribute. After creating the buffer, less-or-equal distance calculations can be done with contains or intersects.
The following work flow is available in RapidMiner: first, in an Execute Script operator we process the data using geographic functions with Groovy and GeoScript (e. g. contains: true/false); then we filter the result set with Filter Examples to only keep examples with the selected criteria (e. g. contains = true or distance < 10).
There are two variants of the example process: one with Cartesian Product and one with Loop Examples. The first version is much faster but needs a huge amount of memory as it has to create very large tables. The second version takes much longer but uses less memory, as it doesn’t need to process „multiplied“ data sets.
For some operations like intersects oder contains, the projection is not relevant (as long as both geometries use the same coordinate system). But we need to specify the border size in buffer, so it is again better to work with a meter based projection. Therefore, the example processes transform the original geometries to EPSG:3416, a projection suitable for Austria.
The process fetches three data sets from the Vienna Open Data Server: Water flows (lines), Bridges (areas) und playgrounds (points). It then uses intersects and intersection to find areas where the bridge is over water. Using buffer, it marks an area around water flows and uses contains to find playgrounds in that area. The result is a list of playgrounds in the vicinity of streams or rivers.
This concludes the series about GIS in RapidMiner for now. The described methods solve a range of problems, and many more can be solved with some creativity. I will surely find use cases and solutions, and describe them here. If something is not clear, please ask: here in the comments, in the RapidMiner Forum or even directly. I wish you a lot of success!
Nach der Einführung und dem Datenimport geht es nun an echte geographische Berechnungen.
Eine der wichtigsten Informationen ist die Distanz von Objekten voneinander oder einem Referenzpunkt. Auch Data-Mining-Verfahren wie k Nearest Neighbors berechnen Distanzen.
Zwei verschiedene Methoden stehen uns zur Verfügung, um Distanzen zwischen zwei Punkten auf der Erdoberfläche zu berechnen: Entweder können wir die Punkte als zweidimensionale Geometrie mit X- und Y-Koordinaten auffassen (die Berechnung ist dann ganz einfach), oder die Distanz auf der Oberfläche des Ellipsoids der Erde ausrechnen. Die zweite Vorgehensweise ist mathematisch natürlich deutlich aufwändiger, liefert aber bei größeren Distanzen (z. B. Orte auf verschiedenen Kontinenten) genauere Daten. Deswegen wird in vielen Anwendungen, die nur Objekte in einem eingeschränkten Gebiet enthalten, auf die erste Methode zurückgegriffen.
Transformation in eine andere Projektion (Koordinatensystem)
Wie in der Einführung ausgeführt müssen wir die Geometrien manchmal in andere Projektionen transformieren, um mit sinnvollen Einheiten wie Meter rechnen zu können. Die Methoden dafür sind in GeoScript enthalten und ihre Anwendung ist recht einfach:
import geoscript.proj.*;
fromProj = new Projection("epsg:4326");
toProj = new Projection("epsg:3035");
projectedGeom = Projection.transform(geom, fromProj, toProj);
Ein fertig anwendbarer RapidMiner-Prozess befindet sich hier. Er braucht drei Parameter, die als Makros im Prozesskontext definiert sind und beim Aufruf angegeben werden können:
GEOM_ATT: Name des Attributs, das die zu transformierende Geometrie (im WKT-Format) enthält
FROM_PROJECTION, TO_PROJECTION: Die EPSG-Nummern der Quell- und Zielprojektion.
Damit lassen sich die Koordinaten leicht von einem allgemeinen Koordinatensystem wie WGS84 (Längen- und Breitengrad, EPSG:4326) in ein gebräuchlicheres wie z. B. ETRS89/Austria Lambert (EPSG:3416) konvertieren. Das werden wir im nächsten Beispielprozess anwenden, um Distanzen zwischen Objekten in Wien, aber auch Fläche und Umfang von Bezirken zu berechnen.
Berechnung von Distanz, Fläche und Umfang
GeoScript enthält dafür einfach anzuwendende Funktionen:
flaeche = geom.getArea();
umfang = geom.getLength();
//Für die Distanz brauchen wir eine zweite Geometrie
distanz = geom1.distance(geom2);
Sobald man das Geometrie-Objekt in einer richtigen Projektion hat, sind die Berechnungen ganz simpel.
getArea() liefert die Fläche eines Polygons oder einer Polygongruppe (Multipolygon); getLength() die Länge einer Linie oder den Umfang eines Polygons, jeweils in den Einheiten der aktuellen Projektion.
Für die Distanz brauchen wir ein zweites Geometrie-Objekt, das nicht unbedingt ein Punkt sein muß – es ist auch möglich, die Distanz zwischen Linien und Flächen zu berechnen.
Der Beispielprozess holt zwei Datensätze vom Open-Data-Portal der Stadt Wien: Museen (Punkte) und Bezirksgrenzen (Polygone). Beide werden aus Längen- und Breitengrad-Koordinaten in eine in Österreich gebräuchliche, meter-basierte Projektion transformiert. Mit getArea() und getLength() werden Fläche und Umfang der Bezirke berechnet. Da der Original-Datensatz diese Information bereits enthält, können wir leicht prüfen, ob die Berechnungen korrekt sind. (Kleine Unterschiede resultieren wohl aus der Rundung der Koordinaten für den CSV-Export.)
Dann wird noch der erste Bezirk selektiert und mit dem Museums-Datensatz zusammengeführt. In diesem kombinierten Datensatz haben wir nun zwei Geometrien, wir können also die Entfernung des Museums von der Innenstadt berechnen. Punkte, die im Polygon des ersten Bezirks liegen, haben die Distanz 0.
Berechnung von Distanzen auf der Erdoberfläche
Die zweite, genauere, aber langsamere Berechnungsmethode kann auch recht einfach angewendet werden. Hierfür importieren wir aus der GeoTools-Library, auf die GeoScript aufbaut, die Klasse GeodeticCalculator. (Die Bibliotheken, die wir in der Einführung für GeoScript übernommen haben, reichen dafür aus, wir müssen also nichts Neues installieren.)
Für diese Methode brauchen wir die Längen- und Breitengrade von zwei Punkten, also WGS84-Koordinaten. (Es gäbe auch die Möglichkeit, transformierte Koordinaten zu verwenden, dafür müßten wir dem GeodeticCalculator auch das Koordinatensystem übergeben.)
Hier ist es wichtig, die Reihenfolge der Koordinatenangaben zu beachten. In anderen Bereichen sind wir gewohnt, X- und Y-Koordinaten in dieser Reihenfolge anzugeben, GIS-Systeme arbeiten jedoch manchmal mit der Reihenfolge Y, X.
Der Beispielprozess enthält die Koordinatenpaare einiger Hauptstädte auf verschiedenen Kontinenten. Mit einem Cartesian Product werden alle Städte mit allen anderen verknüpft und jeweils die Distanzen in km berechnet. (Die berechneten Distanzen habe ich mit PostGIS verifiziert; die Ergebnisse sind sehr genau.) Für diese Distanzen würde eine Berechnung mit der Geometrie-Methode schon sehr große Ungenauigkeiten liefern, hier empfiehlt es sich also sehr, die GeodeticCalculator-Methode zu nutzen.
After the introduction and data import we can start to perform actual geographic calculations.
One of the most important measures is the distance of objects from each other or from a reference point. Distances are also calculated by data mining operations like k Nearest Neighbors.
Two different methods of calculating distances between points on the surface of Earth exist: Either we can pretend that the points are in a two-dimensional geometry with X and Y coordinates (which makes the distance calculation very easy), or we use the actual Earth ellipsoid for the calculation. The second method is very computing-intensive, but it returns more precise results when used on larger distances (e. g. places on different continents). For many operations acting on a limited area, the first method is used.
Transformation to another projection (coordinate system)
As described in the introduction, we often need to transform geometries to different projections so we can use units like meters. Coordinate system transformation is also available in GeoScript, and using it is quite easy.
import geoscript.proj.*;
//Source and destination projections
fromProj = new Projection("epsg:4326");
toProj = new Projection("epsg:3035");
projectedGeom = Projection.transform(geom, fromProj, toProj);
Here is a readily usable RapidMiner process. It takes three parameters that can be specified as macros in the process context. You can overwrite them when calling the process in the Execute Process operator.
GEOM_ATT: Name of the attribute that contains the geometry to be transformed (in WKT format)
FROM_PROJECTION, TO_PROJECTION: The EPSG numbers of the source and target projections
With this process, you can easily transform geometries from a common coordinate system like WGS84 (Latitude and Longitude, EPSG:4326) to a special one, for example ETRS89/Austria Lambert (EPSG:3416). We will use this in the example process for calculating distances between objects in Vienna, Austria and also determine the area and circumference of Vienna’s 23 districts.
Calculating distance, area and circumference
GeoScript contains easy to use functions:
area = geom.getArea();
circumference = geom.getLength();
//We need a second geometry for calculating distance
distance = geom1.distance(geom2);
After having transformed the geometry object into a matching projection, the calculations are really simple.
getArea() returns the area of a polygon or a group of polygons (Multipolygon); getLength() gives the length of a line or the circumference of a polygon in the units of the used projection.
For calculating the distance, a second geometry object is required. It doesn’t need to be a point: it’s also possible to calculate the distance between lines and areas.
The example process fetches two data sets from the Vienna Open Data Portal: Museums (points) and district borders (polygons). The process transforms then from latitude and longitude coordinates into a projection used in Austria. One script calculates the area and circumference of the districts using getArea() and getLength(). The original data set already contains these measures so we can easily check that they’re correct. (Small differences are the consequence of rounding the coordinates for CSV export.)
After that, the first district (Inner City) is selected and joined with the museum data set. The combined data set contains two geometries in a common projection, so we can calculate the distance between the museum and the Inner City. Points in the first district have a distance of 0.
Calculating distances on the surface of Earth
The second calculation method (more precise but slower) can also be used quite easily. For this, we import the class GeodeticCalculator from the GeoTools library, a base component of GeoScript. (The GeoScript libraries installed in the introduction are enough for this, we don’t need to set up more stuff.)
For using this method, we need latitude and longitudes of two points, in other words WGS84 coordinates. (It would be possible to use transformed coordinates by specifying a coordinate system in the GeodeticCalculator.)
Be careful when specifying the coordinates. We usually write X and Y coordinates in this order but GIS tools often use the order Y, X.
The example process contains coordinate pairs of a few capital cities lying on different continents. We build a Cartesian Product of all cities and calculate their distances in kilometers. (The distances were verified with PostGIS, they are very precise.) On these distances, using the geometry method would result in huge inaccuracies, so it’s really better to use the GeodeticCalculator method there.
Shapefile ist ein etabliertes Dateiformat, das zusätzlich zu den Geodaten auch eine Liste von Attributen der abgebildeten Objekte enthalten kann. Die geographischen Objekte können vom Typ Punkt (Point), Linie (LineString) und Polygon sein, jeweils als einzelne oder als Multi-Objekte (MultiPoint usw.).
Meistens bekommt man Shapefile in Form von Zip-Archiven, die die Shape-Datei selbst (*.shp), die Attributdatebank (*.dbf), die Information zur verwendeten Projektion (*.prj) und weitere enthalten.
Wer keine Shape-Datei zur Verfügung hat, findet z. B. bei Geofabrik oder auf Open-Data-Sites (AT, US) welche.
Der RapidMiner-Prozess fürs Einlesen der entpackten Datei ist gleichzeitig eine gute Einführung in die Datenstrukturen von RapidMiner.
Der Prozess steht hier zum Download bereit. Da der Dateiname als Makro im Prozesskontext (View/Show View/Context) definiert wird, steht dieser Prozess als fertiges „Element” zum Einbinden in eigene Prozesse zur Verfügung; der Filename-Parameter wird im aufrufenden Prozess unter „macros” eingetragen.
Nach dem Einlesen der Shape-Datei werden die Metadaten abgefragt (Layer.schema.fields), danach werden die einzelnen Elemente (Features in der GIS-Terminologie) gelesen:
def shp = new Shapefile("%{FILENAME}")
int fields = shp.schema.fields.size();
...
shp.schema.fields.each{f -&gt;
...
fieldMeta[fld] = f;
}
...
shp.features.each { f -&gt;
data = new Object[fields];
fieldMeta.each{ attr -&gt;
data[fld] = f.get(attr.name).toString();
}
fld++;
}
Der RapidMiner-spezifische Teil erzeugt zuerst ein Array mit den Attributen, deren Namen und Datentypen aus den Fields des Shapefile-Schemas aufgebaut werden. Mit dem Attribut-Array wird dann ein ExampleTable erzeugt. Nach dem schrittweise Befüllen des data-Arrays wird jedes Example mit einem DataRowFactory erzeugt und ans ExampleTable angefügt. Dieses wird am Ende in ein ExampleSet umgewandelt und als erster Output ausgegeben.
Das Ergebnis des Skript-Aufrufs ist ein normales RapidMiner-ExampleSet, dessen Metadaten aus dem Shapefile stammen. Numerische Attribute sind entsprechend konvertiert, sodaß der Datensatz ganz normal weiterverwendet werden kann. Handelt es sich um eine Geometrie aus Punkten, kann man sogar leicht die X- und Y-Koordinaten extrahieren und den Datensatz darstellen (in diesem Beispiel Orte in Ungarn):
Shapefile is a popular file format that is able to store geospatial data with additional attributes of each object. Points, LineStrings, Polygons and their Multi-versions (e. g. MultiPoint) are supported.
Usually a “shapefile” is a Zip archive that contains the shape file itself (*.shp), the database of attributes (*.dbf), the projection information (*.prj) and more.
If you don’t have a shapefile for testing yet, you can find some at Geofabrik and on Open Data sites (AT, US).
The RapidMiner process that reads the unpacked file is also a good introduction into the data structures of RapidMiner.
The process is available for download here. The file name is defined in the process context as a macro (View/Show View/Context), so you can use this process as a ready-to-use element in your own processes. Just include the file name to import in the macros entry of the Execute Process operator.
After reading the shapefile, the script determines the metadata of the fields (Layer.schema.fields) and reads the elements (called feature in GIS software).
def shp = new Shapefile("%{FILENAME}")
int fields = shp.schema.fields.size();
...
shp.schema.fields.each{f -&gt;
...
fieldMeta[fld] = f;
}
...
shp.features.each { f -&gt;
data = new Object[fields];
fieldMeta.each{ attr -&gt;
data[fld] = f.get(attr.name).toString();
}
fld++;
}
The RapidMiner specific part creates an array for the attributes and reads their names and data types from the Fields of the shapefile Schema. An ExampleTable is created from the attribute array. After filling a data array step by step, it is converted to a data row using a DataRowFactory and appended to the ExampleTable. This table is converted to an ExampleSet and returned as the first output of the operator.
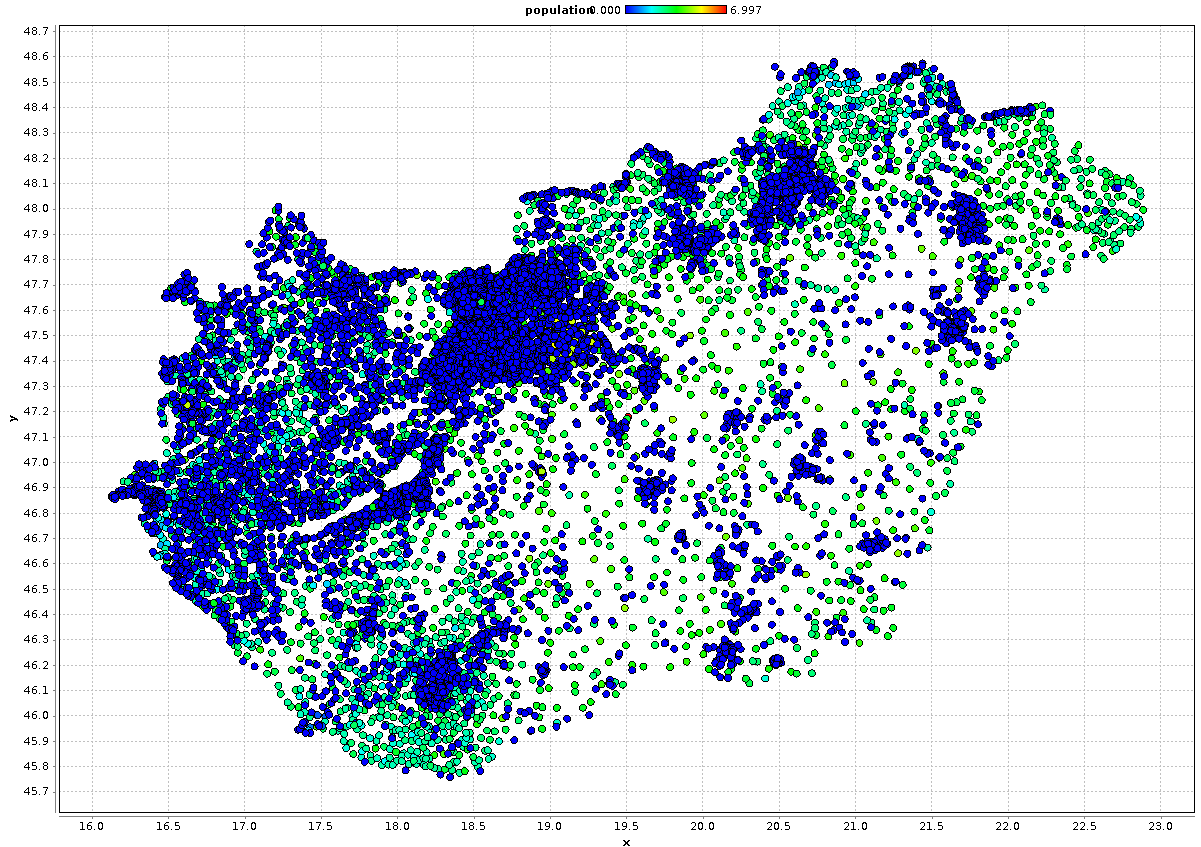
The script execution returns a normal RapidMiner ExampleSet with metadata and data from the shapefile. Numeric attributes are converted correctly. If you have a Point geometry, you can easily extract the X and Y coordinates and display the data in a scatterplot (in this example all places in Hungary).
Es gibt regelmäßig Kundenanfragen nach GIS-Funktionalität in RapidMiner. Leider ist eine solche Funktionalität (noch) nicht im Kern oder in Erweiterungen enthalten. Trotzdem kann man einiges erreichen, wenn man bereit ist, sich etwas in die Materie einzuarbeiten.
Meine bevorzugte Lösung ist, möglichst viel in einer geographischen Datenbankumgebung wie PostGIS zu erledigen. Damit sind die im Folgenden beschriebenen Dinge leicht zu lösen. Leider gibt es nicht überall eine PostGIS-Installation. Es kann also notwendig sein, die Funktionalität in RapidMiner nachzubauen.
In dieser Serie von Posts möchte ich erklären, wie man RapidMiner erweitert, um Geodaten zu verarbeiten und aus ihnen neue Informationen zu gewinnen.
Ziele
Einige Funktionen, die von einer GIS-fähigen Software erwartet werden:
Geodaten aus verbreiteten (Datei-)Formaten lesen
Distanzberechnung zwischen Punkten oder anderen Objekten
Berechnung von Abmessungen von Objekten, etwa Länge, Umfang und Fläche
Identifizierung von Objekten, die sich berühren, enthalten oder überlappen
Selektion von Objekten anhand ihrer Position, Abmessungen oder in Abhängigkeit von anderen Objekten
Damit können wir im Data-Science-Kontext ganz viel machen. Wir können Objekte klassifizieren (z. B. Punkte in einer Stadt, Straßen in der Nähe von Autobahnen usw.), Punkte clustern und Attribute ableiten, die bei der Analyse hilfreich sind. Wir können auch zwei Datensätze im Hinblick auf ihre geographische Lage abgleichen, z. B. Flächen suchen, die sich berühren oder überschneiden.
Koordinatensysteme
Die meisten geographischen Daten, auf die wir im Internet treffen, sind in Längen- und Breitengrad-Koordinaten angegeben. Dieses System hat den Vorteil, daß es einen Punkt auf der Erde mit zwei Zahlen (-90 (Süd) bis +90 (Nord) und -180 (West) bis +180 (Ost) Grad) ausdrückt. Das Problem dieser Darstellung ist jedoch, daß die Distanz zwischen zwei Punkten in Koordinaten nicht leicht zu interpretieren ist. Am Äquator sind die gedachten Linien weiter auseinander als in Mitteleuropa, und am Nord- und Südpol treffen sie sich schließlich in einem Punkt. Deswegen gibt es keine einfache Formel „Ein Längengrad entspricht X Metern”.
Für einige Anwendungen mag das genügen. Um z. B. in einer Stadt den nächsten Punkt B vom Punkt A zu finden, können die simplen Koordinaten sehr wohl verwendet werden. Aber wir können nicht mit Distanzen und Flächenangaben rechnen. In einem größeren Gebiet (Deutschland, Europa, USA…) sind die Unterschiede zwischen einzelnen Koordinatenpaaren auch nicht mehr sauber interpretierbar.
Den Ausweg bieten Koordinatensysteme (oder Koordinatenbezugssysteme, KBS abgekürzt). Sie werden auch „Projektion“ genannt, da mit ihrer Hilfe die ellipsoidförmige Erde in zwei Dimensionen (also auf Papier oder Bildschirm) abgebildet, „projiziert“ wird.
Koordinatensysteme sind üblicherweise für eine bestimmte Region (z. B. ein Land) definiert und erlauben, in üblichen Maßeinheiten wie Meter zu rechnen. Sie stellen sicher, daß die reale Distanz zwischen der Koordinate 100 and der Koordinate 101 (Beispiel) sowohl im Norden als auch im Süden des betreffenden Landes gleich groß ist.
Die verbreiteten Koordinatensysteme sind zentral registriert, sie können mit einer „EPSG-Nummer“ angesprochen werden.
In Deutschland sehe ich häufig Varianten der Gauß-Krüger-Projektion in Verwendung, z. B. EPSG:31468. Für Österreich verwende ich ETRS89/Austria Lambert, EPSG:3416.
Werkzeug-Auswahl und Installation
GeoScript ist ein Skripting-Frontend für andere Open-Source-Bibliotheken (z. B. GeoTools) und andere mit Groovy-Anbindung. Da RapidMiner Groovy-Skripting eingebaut hat, können wir GeoScript verwenden. (Es gäbe auch die Möglichkeit, mit R- oder Python-Skripten in RapidMiner zu arbeiten. Diese sind jedoch eigene Extensions, die zusätzlich installiert und gewartet werden müssen.)
Die Installation birgt einige Tücken. Der GeoScript-Download bringt 218 jar-Archive mit einer Gesamtgröße von 71 MB mit – viele davon werden auch in RapidMiner (teilweise in anderen Versionen) verwendet. Ich warne davor, all diese Jars ins RapidMiner-lib-Verzeichnis zu kopieren – RapidMiner Studio startet dann nicht mehr.
Deswegen müssen die Jars selektiv hineinkopiert werden, solange RapidMiner noch verwendbar ist, aber die gewünschte Funktionalität zur Verfügung steht.
Mein Ansatz ist der folgende: Unter rapidminer-studio/lib erzeuge ich ein Verzeichnis „geoscript”, und kopiere die Libraries dorthin. Danach wird das Startskript von RapidMiner Studio um diesen Classpath erweitert (rmClasspath= … in der sh-Datei).
Ein Zip-Archiv mit meiner Auswahl der Libraries (aus den Projekten GeoScript und GeoTools) liegt hier. Zusätzlich habe ich im rapidminer-studio/lib-Verzeichnis groovy-all-2.3.3.jar in .jar.old umbenannt und groovy-all-2.4.5.jar aus der Groovy-Distribution hineinkopiert.
Verwendung von Geodaten in RapidMiner
Als erstes müssen wir die Daten in RapidMiner hineinbringen. Hierfür gibt es viele Möglichkeiten, beginnend mit Geokoordinaten in CSV-Dateien bis hin zu geographischen Datenbanken.
Shapefile ist ein verbreitetes Dateiformat, in dem die Geodaten mit weiteren Attributen verknüpft sein können. GeoScript kann Shapefiles einlesen, wir können aus ihnen somit ganz normale RapidMiner-ExampleSets machen.
Dann müssen wir eine Repräsentation der Daten finden, mit der RapidMiner umgehen kann. Für Punkte kann es passen, sie als zwei Attribute (latitude und longitude) mitzuführen. Für komplexere Objekte wie Linien (z. B. Straßenverlauf) und Polygone (z. B. Ländergrenzen) reicht es aber nicht.
Es gibt verschiedene Repräsentationsmöglichkeiten für Geometrien: Well Known Text (WKT), Well Known Binary (WKB), GeoJSON usw. GeoScript enthält Konvertierungsfunktionen für diese Formate, wir können also die Geometrie-Objekte in RapidMiner in einem Nominal-Attribut mitführen. Ich habe WKT, WKB und GeoJSON mit großen Mengen von Geometrie-Objekten getestet, in der Verarbeitungsgeschwindigkeit gibt es keine großen Unterschiede.
Für WKT spricht, daß es in GeoScript einfach mit fromWKT() eingelesen und mit toString() ausgegeben werden kann. Für die anderen Formate muß man Reader- und Writer-Objekte bemühen.
Groovy-Skripting in RapidMiner
Eine wichtige Referenz fürs Skripting ist „How to Extend RapidMiner 5”, auch für Version 6.X noch gültig. Darin ist beschrieben, wie ExampleSets erweitert werden. Das brauchen wir, wenn wir mit Hilfe von Geo-Funktionen neue Attribute erstellen. Forum-Beiträge wie dieser ergänzen die Informationen um die Erzeugung ganzer neuer ExampleSets. Damit können wir einen Import aus Geo-Dateiformaten wie Shapefiles realisieren.
Ausblick
Die nächsten Beiträge dieser Serie beschäftigen sich mit dem Import von Shapefiles und anderen Dateiformaten, der Konvertierung zwischen Koordinatensystemen, der Berechnung von Distanzen und Abmessungen von Objekten sowie mit geographischen Operationen.
Customers sometimes ask for GIS functionality in RapidMiner. This functionality is not (yet) built into the core, nor it is available as an extension. However, with a bit of learning, many problems can be solved.
My preferred solution for geographic data processing is a database environment like PostGIS. All the topics I’ll describe here are easily solved there. Unfortunately, not everyone has a PostGIS installation, so it can be necessary to implement the functionality in RapidMiner.
In this series of blog posts I’d like to demonstrate how RapidMiner can be extended to process geodata and gain information from them.
Goals
Some functions expected from a GIS-capable software are:
Import of geographic data from popular (file) formats
Distance calculation between points or other objects
Calculation of metrics like length, circumference or area
Identification of objects that touch, contain or intersect with each other
Selection of objects based on their position, metrics or in dependence on other objects
We can do a lot with these capabilities in a data science context: Classify objects (e. g. points in a city, streets near highways etc.), cluster points, and derive helpful attributes for further analysis. We can also connect two data sets by their geographic position, for example find areas that touch or intersect.
Coordinate systems
Most geographic data on the Internet is coded in latitude and longitude coordinates. This notation is able to express each point on Earth with two numbers: -90 (south) to +90 (north) and -180 (west) to +180 (east). The problem with this representation is the bad interpretability of distance between coordinates. On the equator, the fictive lines are further from each other than in Central Europe, and they even meet on the North and South Poles. So there is no simple formula like “One degree of latitude is X meters”.
This can be good enough for some applications. You can select the nearest point for another point in a city with them. But it’s not possible to calculate distances and areas in meters or other useful units. In a larger area like Germany, Europe or the USA, even the differences between coordinate pairs are not well interpretable.
The solution for this problem is using coordinate systems (also called coordinate reference systems, CRS). They are also called “projections” because they’re used for displaying the ellipsoid of Earth in two dimensions on paper or a screen.
Coordinate systems are usually defined for a particular region like a country and enable calculations in useful units like meters. They make sure that the real distance between coordinates 100 and 101 (for example) is the same both in the northern and the southern
part of the country or region.
There is a central registry of coordinate systems, they can be referred to by using an “EPSG number” in almost any geo-capable software.
In Germany I’ve seen usage of Gauss-Krueger projections like EPSG:31468. For Austria I use ETRS89/Austria Lambert (EPSG:3416).
Tool selection and installation
GeoScript is a scripting frontend for other open source libraries (e. g. GeoTools) and others. It has a Groovy implementation. As RapidMiner also contains Groovy scripting, we can use GeoScript therein. (It would be possible to use R or Python scripts in RapidMiner. But these are separate extensions with additional installation and maintenance.)
Installation is not easy. The GeoScript download contains 218 jar archives weighing 71 MB – some of them are also used in RapidMiner (even some differing versions). It is not advisable to simply copy all of them into the lib directory of RapidMiner – Studio won’t start then.
Therefore, only a selection of the jars must be copied, as long as RapidMiner is still usable, and the desired geographic function is there.
My approach was to create a new subdirectory under rapidminer-studio/lib called “geoscript” and copy the libraries into it. The start script of RapidMiner Studio must be extended to contain the additional subdirectory in the class path (rmClasspath=… in the shell file).
Here is a zip archive of my library selection, copied together from the GeoScript and GeoTools projects. Additionally, I renamed groovy-all-2.3.3.jar to .jar.old in rapidminer-studio/lib and copied groovy-all-2.4.5.jar from the Groovy distribution.
Using geodata in RapidMiner
First we must import the data into RapidMiner. There are many methods for this, from geometries in CSV files to geographic databases.
A popular file format is „shapefile“. It contains the geometries with additional attributes. GeoScript can read shapefiles, so we can import them as normal ExampleSets into RapidMiner.
After importing we need to find a suitable representation of geodata. It is possible to work with two attributes for the latitude and longitude of points, but they’re not suitable for more complex types like LineString (e. g. streets) or Polygon (e. g. countries).
There are different representations of geometries: Well Known Text (WKT), Well Known Binary (WKB), GeoJSON etc. GeoScript contains conversion functions for these and more formats, so we can convert geometries to a string representation to store them in a Nominal attribute in RapidMiner. I tested WKT, WKB and GeoJSON with a huge number of geometry objects, the processing speed is not really different.
WKT can be read by GeoScript using the fromWKT() function and written with toString(). This is easier than with the other formats which require the usage of Reader and Writer objects.
Groovy scripting in RapidMiner
An important reference for scripting RapidMiner is „How to Extend RapidMiner 5„, still valid for version 6.
It describes the manipulation of ExampleSets and the creation of additional attributes. We need this for creating new attributes with geographic functions. Forum posts like this describe the creation of entirely new ExampleSets. This enables the import of geographic data files like shapefiles.
Preview
The next parts of this series of blog posts will describe the import of shapefiles and other geographic data, conversion between coordinate systems, calculation of distances and measures, and geographic operations.
Im Pentaho BI Server ist eine sehr flexible Karten-Komponente enthalten, die leider nicht gerade ausführlich dokumentiert ist. Ich möchte hier eine kurze Anleitung für einen erfolgreichen Start geben.
Zuerst braucht man Positionsdaten. Diese liegen entweder als echte Geodaten (z. B. aus einer GIS-Datenbank wie PostGIS) oder als Breiten- und Längengrad (latitude/longitude) vor. Im Dashboard brauchen wir die lat/lon-Darstellung.
Als erstes legen wir im Layout-Panel des Dashboard-Editors einen Bereich für die Karte an, z. B. eine Zeile und darin eine Spalte, in diesem Beispiel mit einer Breite von 10 Elementen (Medium Devices). Diese Spalte benennen wir so, daß die Verbindung zum Map-Element erkennbar ist, z. B. MapDiv.
Datenquelle
Die Datenquelle für die Punkte auf der Karte definieren wir im Datasources Panel. Hier legen wir eine Abfrage namens MapQuery an, die uns die Geokoordinaten liefert. Diese Spalten müssen „Latitude“ und „Longitude“ heißen (die Klein- oder Großschreibung ist egal).
Hat man echte Geodaten in einer GIS-fähigen Datenbank, sind die Punkte eventuell in einer eigenen Spalte zusammengesetzt gespeichert. Das läßt sich leicht in die benötigten Koordinaten aufspalten:
SELECT ST_X(ST_Transform(geo, 4326)) as longitude,
ST_Y(ST_Transform(geo, 4326)) as latitude
FROM gis_table
In diesem Beispiel ist „geo“ der Name der Geodaten-Spalte. Mit ST_Transform(geo, 4326) konvertiert PostGIS die Koordinaten aus der in der Datenbank verwendeten Projektion in Länge- und Breitengrad. ST_X und ST_Y extrahieren aus dem konvertierten Objekt die einzelnen Koordinaten.
Karten-Komponente
Jetzt kann das Karten-Element im Components Panel angelegt werden: Custom: NewMapComponent.
Als Name wählen wir in diesem Beispiel einfach „Map“. Als Datasource tragen wir den Namen der Datenquelle (MapQuery) ein, und als HtmlObject den Namen des angelegten Bereichs (MapDiv).
Wenn wir das Dashboard speichern und ausführen, stellen wir fest, daß keine Karte angezeigt wird. Das liegt daran, daß die Karten im Gegensatz zu anderen Elementen selbst keinen Platz beanspruchen. Wir müssen also Breite und Höhe des enthaltenden Elements festlegen, entweder im Layout Panel mit Height, oder in einem Stylesheet.
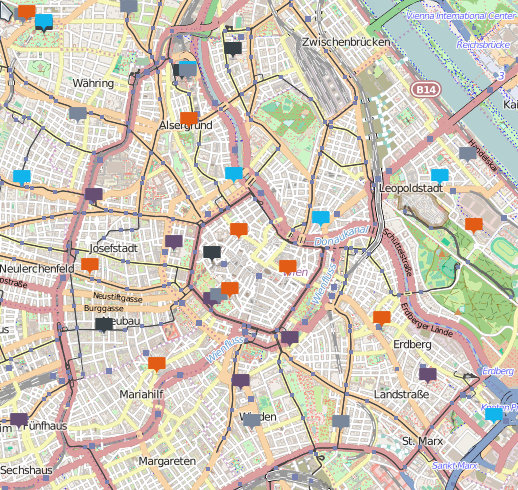
Das Ergebnis der Mühen ist eine Karte, in der die Punkte aus der Datenbankabfrage mit farbigen Standard-Symbolen markiert sind.
Büchereien in Wien – Kartendaten (c) OpenStreetMap contributors
Standardmäßig zeigt die Karte die ganze Erde an. Meist will man aber eine kleinere Region anzeigen. Das geht mit den Optionen Center Latitude und Center Longitude sowie Default Zoom Level.
Die beiden Center-Koordinaten kann man von der Karte ablesen, wenn man mit der Maus über sie fährt. Der Zoom Level hängt von der Größe der Kartendarstellung und dem darzustellenden Gebiet ab. Für eine Großstadt kann der Zoom ca. 12 betragen, Österreich paßt bei Zoom 7 ganz gut, Deutschland braucht schon Zoom 6.
Anpassung der Marker
Die Standard-Markierungen der Punkte auf der Karte passen nicht zu jeder Anwendung. Es besteht die Möglichkeit, eigene Symbole anzuzeigen: dazu gibt man in der Datenquelle die URL zum Symbol (ganz normale Bilddatei) in der Spalte „marker“ aus. Damit lassen sich zum Beispiel unterschiedliche Zustände der dargestellten Objekte anzeigen.
Popups
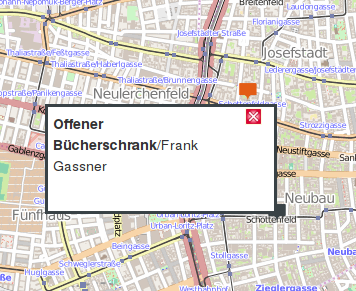
Zu jedem Marker können wir Zusatzinformationen anzeigen lassen. Wenn die Datenquelle eine Spalte „popupContents“ enthält, wird deren Inhalt (optional HTML-formatiert) angezeigt, wenn der Benutzer ein Marker-Symbol anklickt. Mit Popup Width und Popup Height läßt sich die Größe des Popups an den erwarteten Inhalt anpassen.
Beispiel eines formatierten Popups – Kartendaten (c) OpenStreetMap contributors
Mit diesen Optionen läßt sich schon ganz ohne Programmierung viel machen. Mit etwas JavaScript läßt sich noch viel mehr erreichen.
Automatische Aktualisierung der Karteninhalte
Im Gegensatz zu vielen anderen Dashboard-Komponenten bietet NewMapComponent keine Funktion zum automatischen Aktualisieren des Inhalts in festgelegten Abständen. In einigen Fällen möchte man jedoch die Positionen beweglicher Objekte darstellen und die Karte von Zeit zu Zeit automatisch aktualisieren. Glücklicherweise läßt sich das mit ein wenig JavaScript-Code erreichen.
In den Advanced Properties der Karten-Komponente geben wir in der Eigenschaft Post Execution eine Funktion ein:
//Sets up a timer to refresh the map after a minute
function () {
this.timerId = window.setTimeout(
function() {
render_Map.update();
}
, 60000);
}
60000 ist die Anzahl der Millisekunden, nach denen der Timer laufen soll. render_Map ist der Name der Karten-Komponente, mit „render_“ davor – so benennt das Community Dashboard Framework das JavaScript-Objekt.
Da diese Funktion immer nach dem Aktualisieren der Karte ausgeführt wird, ist gleich der nächste Timer nach der gleichen Periode aktiviert. Die Timer-ID, die in JavaScript zum Abbrechen des Timer genutzt werden kann, wird dabei im render_Map-Objekt gespeichert.
Es gibt nur ein Problem: Verschiebt der Benutzer den Kartenausschnitt oder zoomt hinein oder hinaus, setzt die Aktualisierung der Karte den Ausschnitt und den Zoom-Wert auf die Standardwerte. Die Karte kehrt also zum Ausgangspunkt zurück. Um das zu vermeiden, können wir vor dem Update noch schnell die aktuelle Sicht abspeichern, wodurch die Karte nicht mehr springt.
Folgende Funktion gehört in die Pre Execution-Eigenschaft:
//Before reloading the map automatically, save the current zoom level and position
function () {
if (this.timerId != null) {
//Get current map center and zoom level
center = this.mapEngine.map.center;
zoom = this.mapEngine.map.zoom;
//Transform to WGS84 coordinates
center.transform(this.mapEngine.map.projection, "EPSG:4326");
this.defaultZoomLevel = zoom;
this.centerLongitude = center.lon;
this.centerLatitude = center.lat;
}
}
Zuerst überprüfen wir, ob die timerId schon gesetzt ist. Beim ersten Anzeigen der Karte (wenn das Dashboards geöffnet wird) ist das noch nicht der Fall.
Ist die Karte schon fertig dargestellt worden, ist timerId beim nächsten Durchlauf nicht mehr leer, dann können wir also die Position und den Zoom-Level der Karte abfragen und in die Standardeinstellung der Komponente hineinschreiben.
Bei der nächsten automatischen Aktualisierung der Karte tritt zwar ein systembedingtes Flackern auf, aber der vom Benutzer gewählte Bildausschnitt bleibt bestehen.
Die Map-Komponente bietet noch andere Möglichkeiten, so wie das Thema der GIS-Daten ein fast unerschöpfliches ist. Ich werde sicher noch weitere Beiträge in diesem Themenkreis schreiben.
Displaying maps with the Pentaho Dashboard Framework
Pentaho BI Server contains a map component that’s very versatile but unfortunately quite sparsely documented. I’d like to give you a simple introduction into using the component.
First, we need position data. These are either stored in a real geographic database like PostGIS or separated into latitude and longitude. The dashboard map needs the lat/lon form.
First we create an area for the map in the Layout Panel of the Dashboard Editor. This can be a row and a column in it, for example with a width of 10 elements (enter it in the Medium Devices setting). We name this column MapDiv to state that it belongs to the map.
Data source
We need to specify the data source of the points in the Datasources Panel. Here, we enter a query called MapQuery that returns the coordinates. The columns must be called „Latitude“ and „Longitude“ (capitalization doesn’t matter).
Geograpic data in a GIS-capable database stores the points in a single column. It is easy to separate the two coordinates:
SELECT ST_X(ST_Transform(geo, 4326)) as longitude,
ST_Y(ST_Transform(geo, 4326)) as latitude
FROM gis_table
In this example, „geo“ is the name of the geodata column. In PostGIS, ST_Transform(geo, 4326) converts the coordinates from the geographic reference system used in the database to the classic Earth latitude and longitude values. ST_X and ST_Y extract the longitude and latitude from the compound object.
Map component
Now we create the Map element in the Components Panel by adding a Custom: NewMapComponent.
The name is simply „Map“ in this example. The Datasource is the name of our data source (MapQuery) and the HtmlObject is the name of the created row (MapDiv).
After saving and executing the dashboard, no map is shown. The reason is that the Map component itself doesn’t specify a content height, as other components do. So we need to set the width and height ourselves, either in the Layout Panel (Row Height) or in a stylesheet.
The result is a map that visualizes points from the database query with standard symbols in different colors.
By default, the map shows the entire Earth. We usually want to restrict the displayed area: this is done with the options Center Latitude/Longitude and Default Zoom Level.
The Center coordinates are displayed on the map when moving the mouse over it. The zoom level depends on the size of the map and the area to be shown. For a large city, the zoom can be around 12, Austria fits well with zoom = 7, and Germany requires zoom = 6.
Changing the markers
The default markers of map points aren’t suitable for some requirements. It is possible to use our own symbols: just return the URL of the symbol (a normal image file) in the column called „marker“ in the map data source. This allows us to visualize different object states.
Popups
For each marker we can display additional information in a popup area. If the data source contains a column named „popupContents“, its text (optionally HTML formatted) is displayed when the user clicks on a marker symbol. Popup Width and Popup Height can be changed to match the size of the content to display.
Using these options, we can already do a lot, entirely without programming. A bit of JavaScript can do a lot more.
Periodic updates of the map contents
In contrast to many other dashboard components, the NewMapComponent doesn’t have a setting for periodic updates. Sometimes we have to visualize objects that can move and automatically refresh the map from time to time. Fortunately, only a few lines of simple JavaScript are necessary to achieve this.
We enter the following function in the Advanced Properties of the Map component, in the property Post Execution:
//Sets up a timer to refresh the map after a minute
function () {
this.timerId = window.setTimeout(
function() {
render_Map.update();
}
, 60000);
}
60000 is the number of milliseconds after the timer executes the function. The map component is named render_Map in this example: the Community Dashboard Framework always prefixes the specified names with „render_“ to create the JavaScript object in the running dashboard.
This function is executed after each update of the map, so it also sets up the next automatic update after the same period. The timer ID stored in the render_Map object could be used to cancel the timer if desired.
However, there’s one usability problem: If the user moves the map or zooms in, the automatic update resets the map to the values defined in the dashboard properties and the map returns to the initial view. We can avoid this by storing the properties of the current view before the map update, so the map doesn’t jump around anymore.
The following function is entered into the Pre Execution property:
//Before reloading the map automatically, save the current zoom level and position
function () {
if (this.timerId != null) {
//Get current map center and zoom level
center = this.mapEngine.map.center;
zoom = this.mapEngine.map.zoom;
//Transform to WGS84 coordinates
center.transform(this.mapEngine.map.projection, "EPSG:4326");
this.defaultZoomLevel = zoom;
this.centerLongitude = center.lon;
this.centerLatitude = center.lat;
}
}
The function checks if the timerId is set. If the map is displayed the first time (when opening the dashboard), this is not yet the case.
In a map that is already displayed, the timerId has a value, so we can store the map’s position and zoom level in the properties of the map object.
The map update causes a visible flicker of the dashboard, but at least the map area selected by the user stays as it is.
The map component offers a lot more, and GIS data is an almost infinite topic. This blog post isn’t the last one about maps, that’s for sure.