Als vor 1-2 Jahren die ostasiatischen Leihfahrrad-Anbieter mitteleuropäische Städte mit ihren Billigrädern zur Miete überfluteten, war die Preispolitik ein wichtiger Punkt in der Diskussion. Es war mehr oder weniger Konsens, daß es den Anbietern langfristig nicht um die wenigen Cent für die Kundenfahrten geht, sondern um die Bewegungsdaten der Kunden.
Jetzt sind E-Tretroller der letzte Schrei, in Wien stehen schon drei Anbieter. Sie müssen ihre Tretroller jeden Abend einsammeln und in der Früh rausbringen, sie zwischendurch aufladen, die Funktion prüfen und warten. Das ist angesichts der Kosten von Arbeit in Österreich schon ein gewagtes Geschäftsmodell. Die theoretische Bewertung der beiden US-Anbieter liegt laut Medien im Milliarden-Bereich. Hierzu gibt es wieder die Annahme, daß zukünftige Einnahmen nicht nur durch die (ziemlich günstigen) Kundenfahrten, sondern durch Auswertung und Verkauf der Bewegungsdaten generiert werden können.
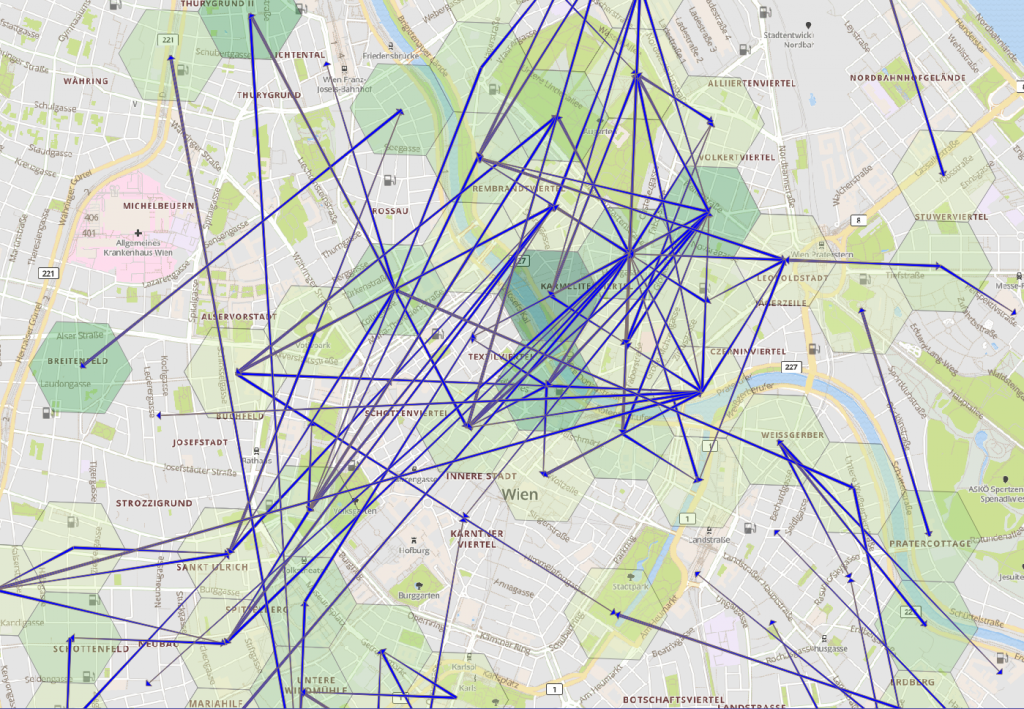
Hexagonale Felder, aus denen viele SCO2T-Fahrten ausgingen, Ziele der Fahrten. Anzahl der Fahrten durch die Dicke der Pfeile angedeutet.
Denken wir dieses Geschäftsmodell mal für Europa durch. In der EU gelten strenge Datenschutz-Vorschriften, es ist also zumindest legal nicht möglich, Daten wie „XY ist am 1.12.2018 von A nach B gefahren“ zu verkaufen. Sehr wohl kann man aber Daten aggregieren und Dinge auswerten wie „Aus dem Bereich von Alt-Erlaa in den Bereich der UNO-City fahren am Tag durchschnittlich 7 Menschen, 4 davon am Vormittag, 2 am Nachmittag und 1 am Abend“. Nur, wer fragt solche Informationen nach, und wie viel ist er/sie bereit, dafür zu zahlen? Die Stadt Wien, VerkehrsplanerInnen, vielleicht Firmen, die autonomes Fahren entwickeln, andere Verkehrsdienstleister. Nur wird diese Art von Information schon entweder selbst erhoben (die Wiener Linien können das z. B. sicherlich zählen), oder seit Jahren etwa von Mobilfunkfirmen angeboten.
Bei SCO2T haben wir in mehr als vier Jahren, mit vielen tausend Fahrten pro Monat, mit einer großen Präsenz in Fachkreisen und bei Konferenzen, keine einzige Anfrage in diese Richtung bekommen. Das deutet für mich eher darauf hin, daß dieser Markt für aggregierte Bewegungsdaten (noch) nicht existiert, zumindest nicht in Wien.
Neben dem Verkauf der Daten kann man sie natürlich auch intern analysieren, damit Prozesse optimieren und die Dienstleistung für die Kunden verbessern. Z. B. können wir die Scooter nach einer Servicefahrt dort abstellen, wo die Wahrscheinlichkeit einer neuen Miete am höchsten ist. Für diese Analyse sind die Daten von vergangenen Fahrten ohne Kundenbezug notwendig. (SCO2T bezieht grundsätzlich keine personenbezogenen Daten von Kunden in solche Analysen ein — es ist einfach nicht notwendig.)
Meine Schlußfolgerung: Ich als Data Scientist mit GIS-Erfahrung und direktem Zugang zu entsprechenden Bewegungsdaten sehe keinen großen legalen Markt für den Verkauf dieser Daten.
Natürlich könnten Anbieter auf illegale (oder zumindest im Kleingedruckten versteckte und unmoralische) Ideen kommen. Z. B.: Kunde A ist schon öfter ins Donauzentrum gefahren und ist wieder auf dem Weg dorthin. Voraussichtliche Ankunft: 13:30. Wenn man diese Information an Google weitergeben kann, könnte ich mir vorstellen, daß dafür einige Cent gezahlt werden — schließlich kann der Person dann zur richtigen Zeit ortsbezogene Werbung gezeigt werden. Diese Geschäftsmodelle existieren in den USA, und werden als Zukunft der Werbung angesehen — ich sehe aber nicht, wie sie mit der DSGVO vereinbar wären, außer mit expliziter Zustimmung der Kunden. Und selbst wenn — Milliarden wird man damit auch nicht verdienen (nur Google).
Richtige Datenbankserver wie PostgreSQL haben seit geraumer Zeit den SQL-99-Standard umgesetzt, der unter anderem Window Functions beschreibt.
Mit Window Functions lassen sich gruppenbezogene Statistiken und Kennzahlen berechnen, ohne die Ergebnismenge zu gruppieren. (Dies ist der Unterschied zur klassischen Aggregierung mit GROUP BY.) Es gibt eine Menge Anwendungsbeispiele: es lassen sich laufende Summen, gleitende Mittelwerte, Anteile innerhalb der Gruppe, gruppenweise Minima oder Maxima und noch viele andere Dinge berechnen. Manche Leute meinen, daß mit Window Functions eine neue Ära für SQL begonnen hat, und ich neige dazu, ihnen zuzustimmen.
RapidMiner hat bislang keine Window Functions eingebaut. Erfahrene Data Scientists, die Bedarf an dieser Funktionalität hatten, haben diese mit verschiedenen Operatoren (Loops, gruppenweise Aggregation und Join usw.) selbst nachbauen können, aber das ist alles andere als trivial.
Um die Funktionalität für einen größeren Benutzerkreis zu öffnen und gleichzeitig eine wiederverwendbare Implementierung zu schaffen, habe ich das Projekt rapidminer-windowfunctions ins Leben gerufen und eine erste funktionierende Implementierung hochgeladen.
Alle im RapidMiner-Operator „Aggregate“ eingebauten Aggregationsfunktionen lassen sich verwenden: sum, average, minimum, maximum usw. Zusätzlich sind die Funktionen row_number, rank und dense_rank verfügbar.
Im Projektordner sind der eigentliche Prozess und aktuell drei Beispielprozesse enthalten, um gleich verschiedene Anwendungsmöglichkeiten testen zu können.
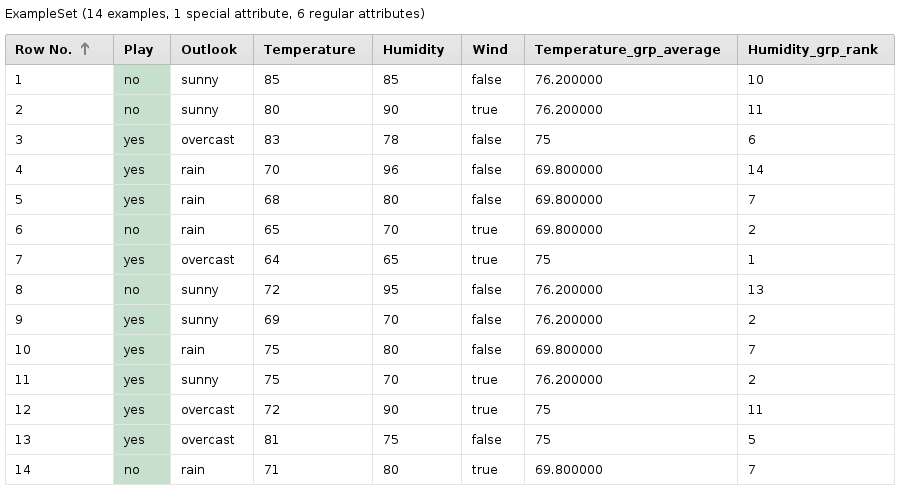
Golf-Datensatz: Gruppenmittelwert der Temperatur und Rang innerhalb der Gruppe für Luftfeuchtigkeit
Golf: Der berühmte Golf-Dataset wird aus dem mitgelieferten Beispiel-Repository geladen. Für jede Gruppe basierend auf dem „Outlook“-Attribut wird die Durchschnittstemperatur berechnet und als Attribut hinzugefügt. Ein zweites neues Attribut enthält den Rang des Datensatzes bei Sortierung nach dem Wert der Luftfeuchtigkeit. Gleiche Werte erhalten den gleichen Rang.
Iris: Ein weiterer Standard-Dataset, Iris, wird geladen, und es wird pro Spezies der Durchschnittswert fürs Attribut „a3“ berechnet. Dieser Mittelwert wird dann genutzt, um Exemplare herauszufiltern, die mehr als 10 % vom Gruppenmittelwert entfernt sind.
Deals: Der mitgelieferte Dataset „Deals“ wird geladen. In jeder Kundengruppe aus Geschlecht und Zahlungsmethode werden die drei ältesten Kunden gesucht, die anderen werden herausgefiltert.
Das zeigt schon die Bandbreite der Möglichkeiten, die Window Functions bieten. Die Möglichkeit, sie leicht einzusetzen und Indikatoren sowie Kennzahlen wie „Transaktionszähler des Kunden im Monat“, „Anteil des Produkts an der Monatssumme“ und ähnliche erzeugen zu können, wird viele Prozesse vereinfachen, oder neue Möglichkeiten eröffnen.
Implementierung
Nach einigen Prüfungen, z. B. ob die benötigten Makros gesetzt sind, werden neue Attribute zur Gruppierung und Identifizierung von Examples angelegt. Das zusammengesetzte Gruppierungsattribut wird dabei aus den Werten der als groupFields angegebenen Attribute generiert. Das Identifizerungs-Attribut muß mit einem Groovy-Skript generiert werden, da Generate Id mit vielen Datensätzen nicht funktionieren würde. (Generate Id funktioniert nicht, wenn der Datensatz bereits ein Attribut mit der Rolle id enthält.)
Die drei Spezialfunktionen, die in Aggregate nicht enthalten sind, werden gesondert behandelt. Die Untergruppen werden nach dem ausgewählten Attribut sortiert und der Datensatzzähler bzw. die Rangfolge berechnet.
Die Standard-Aggregierungsfunktionen von RapidMiner werden einfach auf jede Subgruppe angewendet, dabei entsteht jeweils eine gruppierte Zeile. Diese wird wieder mit den Originaldaten gejoint.
Einschränkungen
Gegenüber dem SQL-Standard und der in Datenbanken implementierten Funktionalität fehlt noch einiges. Z. B. erlauben Datenbanken bei Funktionen wie SUM die Angabe eines Sortierkriteriums und berechnen dann eine kumulierte Summe für jede Zeile, statt die gleiche Summe wiederholt auszugeben.
Der Prozess ist auch recht langsam, wenn viele Gruppen existieren. Dies ergibt eine große Anzahl von Filterungen in der Schleife. Bei den speziellen Rang- und Zählerfunktionen ist das Problem besonders ausgeprägt, da in jedem Durchlauf ein Groovy-Interpreter gestartet wird, was erhebliche Zeit kostet.
Das Konzept von Window-Definitionen geht in SQL-Datenbanken über Selektion von Gruppen hinaus. Z. B. kann man in SQL auf den vorherigen oder nächsten Datensatz zugreifen (LAG bzw. LEAD), ein fixes Fenster von X Zeilen definieren, und in den Daten „nach vorne“ schauen. Diese Dinge sind gegenwärtig nicht im Prozess eingebaut.
Mögliche Erweiterungen
Es spricht nichts dagegen, einige von den in SQL zur Verfügung stehenden Funktionen wie percent_rank, ntile oder first/last_value einzubauen. Dies wird bei Bedarf sicher passieren.
Die Funktionalität, über ORDER BY das Verhalten der Aggregierungsfunktionen zu ändern (z. B. für kumulierte Summen), erscheint mit RapidMiner-Mitteln nicht einfach. Allerdings ließe sich die kumulierte Summe leicht mit einem weiteren Groovy-Skript implementieren.
Bezugsquelle
Das Projekt kann auf Github heruntergeladen oder ausgecheckt werden. Es enthält Dokumentation und Beispielprozesse. Die Lizenz ist Apache 2.0, somit sind Einsatz und Weiterentwicklung uneingeschränkt möglich. Es ist also ein klassisches Open-Source-Projekt, das von der Beteiligung und Weiterentwicklung durch die Community leben soll.
Window functions in RapidMiner
For powerful database software like PostgreSQL the SQL-99 standard has been implemented for a long time. Window functions are an important part of SQL-99.
Window functions are used for calculating groupwise statistics and measures without actually grouping the result. (This is the difference between Window functions and the well-known aggregation with GROUP BY.) There are many applications: running sums, moving averages, ratios inside a group, groupwise minimum and maximum and so on. Some people consider the introduction of Window functions the beginning of a new era for SQL. I agree with this quite strongly.
RapidMiner doesn’t offer Window functions, yet. Experienced data scientists were able to build this functionality when they had to, using loops, aggregation and join, but these processes are not easy to create and debug.
My goal is to open this functionality for a larger group of potential users and to create a reusable implementation. So I started the rapidminer-windowfunctions project and uploaded the first working version.
All functions built into RapidMiner’s Aggregate operator can be used: sum, average, minimum, maximum etc. Additional functions are row_number, rank and dense_rank.
The project ships with the actual process and a number of example processes. These demonstrate different applications of Window functions on public datasets available in RapidMiner Studio.
Golf dataset with groupwise temperature average and rank by humidity
Golf: The process loads the well-known Golf dataset from the Samples repository. For each group defined by the attribute “Outlook”, the average temperature gets calculated. A second attribute ranks the examples by the attribute “Humidity”. Identical values get the same rank.
Iris: This is another standard dataset, available from RapidMiner’s Samples repository. The process calculates the average value for the attribute “a3”. This group average is used to filter out examples which differ from the average by more than 10 %.
Deals: Another data set built into RapidMiner. This process considers all combinations of Gender and Payment Method as groups and ranks the customers based on their age. Only the 3 oldest customers per group are retained.
This is just a small sample of all the functionality available with Window Functions. Being able to use them easily for building indicators and measures like “transaction counter per customer and month” or “the product’s contribution percentage” will open new possibilities for modelling or reporting.
Implementation
The process checks a few preconditions, for example required parameter macros. It creates new attributes for grouping and identifying examples. The grouping attribute is built from all values given in the groupFields parameter. The identifying attribute needs to be generated in a Groovy script, as Generate Id would fail on too many real-world datasets. (It doesn’t work when the dataset already has an attribute with the role id.)
The three special functions not available in Aggregate are implemented with Groovy scripts. The process sorts the subgroups by the selected attributes and calculates the record counter or the rank.
The implementation of the standard aggregations is simpler: each subgroup is aggregated and the result is joined with the original data.
Limitations
Some functionality is missing compared to the SQL standard and to database systems. For example, in SQL databases, you can use ORDER BY in the window function to specify an ordering and calculate cumulative sums for each row instead of a groupwise sum.
The process is quite slow if many groups exist in the dataset. Having many groups results in a large number of filters in the loop. The performance is especially bad with the special ranking and counter functions because they start a Groovy interpreter in each iteration, which takes a lot of time compared to other operators.
The concept of window definition in SQL databases covers more than just the selection of groups. For example, you can access the previous and next records (LAG and LEAD), define a fixed window of N rows, and look forward in the data. These things are not available in the current version of the process.
Possible extensions
It’s entirely possible to implement more SQL standard functions like percent_rank, ntile and first/last_value. This will happen for sure when there’s a need.
It seems to be hard to change the behaviour of aggregation functions using ORDER BY (e. g. for cumulative sums) with RapidMiner means. However, special cases like the cumulative sum could be implemented with another Groovy script.
Getting the process
You can download the process or check it out on Github. The project also contains documentation and example processes. The license is Apache 2.0, so there are no restrictions on usage or further development. It is intended to become an Open Source project with the participation of and further development by the community.
Die nächsten RapidMiner-Trainings in Wien (Basics 1 + 2: Einführung in Datenvorverarbeitung und Predictive Analytics/Data Mining mit RapidMiner) halte ich ab 9. Mai 2016. Es sind jeweils 2 Tage, also insgesamt 4.
Die Anmeldung ist hier möglich. Wir sind wieder bei Data Technology zu Gast.
Seit einiger Zeit gibt es „RapidMiner-Sprechstunden”, bei denen ein Experte ein bestimmtes Thema per Webcasting vorstellt. Während der Sprechstunde kann man auch Fragen stellen; die Aufzeichnung ist dann auf Youtube verfügbar.
Ich werde am 20. April und dann am 1. Juni die Sprechstunde leiten.
Am 20. 4. ist „Geographic Processing and Visualization“ das Thema (auf Basis meiner Blogserie GIS in RapidMiner), am 1. 6. dann „Access Google Analytics using RapidMiner“.
Nach der Einführung und dem Datenimport geht es nun an echte geographische Berechnungen.
Eine der wichtigsten Informationen ist die Distanz von Objekten voneinander oder einem Referenzpunkt. Auch Data-Mining-Verfahren wie k Nearest Neighbors berechnen Distanzen.
Zwei verschiedene Methoden stehen uns zur Verfügung, um Distanzen zwischen zwei Punkten auf der Erdoberfläche zu berechnen: Entweder können wir die Punkte als zweidimensionale Geometrie mit X- und Y-Koordinaten auffassen (die Berechnung ist dann ganz einfach), oder die Distanz auf der Oberfläche des Ellipsoids der Erde ausrechnen. Die zweite Vorgehensweise ist mathematisch natürlich deutlich aufwändiger, liefert aber bei größeren Distanzen (z. B. Orte auf verschiedenen Kontinenten) genauere Daten. Deswegen wird in vielen Anwendungen, die nur Objekte in einem eingeschränkten Gebiet enthalten, auf die erste Methode zurückgegriffen.
Transformation in eine andere Projektion (Koordinatensystem)
Wie in der Einführung ausgeführt müssen wir die Geometrien manchmal in andere Projektionen transformieren, um mit sinnvollen Einheiten wie Meter rechnen zu können. Die Methoden dafür sind in GeoScript enthalten und ihre Anwendung ist recht einfach:
import geoscript.proj.*;
fromProj = new Projection("epsg:4326");
toProj = new Projection("epsg:3035");
projectedGeom = Projection.transform(geom, fromProj, toProj);
Ein fertig anwendbarer RapidMiner-Prozess befindet sich hier. Er braucht drei Parameter, die als Makros im Prozesskontext definiert sind und beim Aufruf angegeben werden können:
GEOM_ATT: Name des Attributs, das die zu transformierende Geometrie (im WKT-Format) enthält
FROM_PROJECTION, TO_PROJECTION: Die EPSG-Nummern der Quell- und Zielprojektion.
Damit lassen sich die Koordinaten leicht von einem allgemeinen Koordinatensystem wie WGS84 (Längen- und Breitengrad, EPSG:4326) in ein gebräuchlicheres wie z. B. ETRS89/Austria Lambert (EPSG:3416) konvertieren. Das werden wir im nächsten Beispielprozess anwenden, um Distanzen zwischen Objekten in Wien, aber auch Fläche und Umfang von Bezirken zu berechnen.
Berechnung von Distanz, Fläche und Umfang
GeoScript enthält dafür einfach anzuwendende Funktionen:
flaeche = geom.getArea();
umfang = geom.getLength();
//Für die Distanz brauchen wir eine zweite Geometrie
distanz = geom1.distance(geom2);
Sobald man das Geometrie-Objekt in einer richtigen Projektion hat, sind die Berechnungen ganz simpel.
getArea() liefert die Fläche eines Polygons oder einer Polygongruppe (Multipolygon); getLength() die Länge einer Linie oder den Umfang eines Polygons, jeweils in den Einheiten der aktuellen Projektion.
Für die Distanz brauchen wir ein zweites Geometrie-Objekt, das nicht unbedingt ein Punkt sein muß – es ist auch möglich, die Distanz zwischen Linien und Flächen zu berechnen.
Der Beispielprozess holt zwei Datensätze vom Open-Data-Portal der Stadt Wien: Museen (Punkte) und Bezirksgrenzen (Polygone). Beide werden aus Längen- und Breitengrad-Koordinaten in eine in Österreich gebräuchliche, meter-basierte Projektion transformiert. Mit getArea() und getLength() werden Fläche und Umfang der Bezirke berechnet. Da der Original-Datensatz diese Information bereits enthält, können wir leicht prüfen, ob die Berechnungen korrekt sind. (Kleine Unterschiede resultieren wohl aus der Rundung der Koordinaten für den CSV-Export.)
Dann wird noch der erste Bezirk selektiert und mit dem Museums-Datensatz zusammengeführt. In diesem kombinierten Datensatz haben wir nun zwei Geometrien, wir können also die Entfernung des Museums von der Innenstadt berechnen. Punkte, die im Polygon des ersten Bezirks liegen, haben die Distanz 0.
Berechnung von Distanzen auf der Erdoberfläche
Die zweite, genauere, aber langsamere Berechnungsmethode kann auch recht einfach angewendet werden. Hierfür importieren wir aus der GeoTools-Library, auf die GeoScript aufbaut, die Klasse GeodeticCalculator. (Die Bibliotheken, die wir in der Einführung für GeoScript übernommen haben, reichen dafür aus, wir müssen also nichts Neues installieren.)
Für diese Methode brauchen wir die Längen- und Breitengrade von zwei Punkten, also WGS84-Koordinaten. (Es gäbe auch die Möglichkeit, transformierte Koordinaten zu verwenden, dafür müßten wir dem GeodeticCalculator auch das Koordinatensystem übergeben.)
Hier ist es wichtig, die Reihenfolge der Koordinatenangaben zu beachten. In anderen Bereichen sind wir gewohnt, X- und Y-Koordinaten in dieser Reihenfolge anzugeben, GIS-Systeme arbeiten jedoch manchmal mit der Reihenfolge Y, X.
Der Beispielprozess enthält die Koordinatenpaare einiger Hauptstädte auf verschiedenen Kontinenten. Mit einem Cartesian Product werden alle Städte mit allen anderen verknüpft und jeweils die Distanzen in km berechnet. (Die berechneten Distanzen habe ich mit PostGIS verifiziert; die Ergebnisse sind sehr genau.) Für diese Distanzen würde eine Berechnung mit der Geometrie-Methode schon sehr große Ungenauigkeiten liefern, hier empfiehlt es sich also sehr, die GeodeticCalculator-Methode zu nutzen.
After the introduction and data import we can start to perform actual geographic calculations.
One of the most important measures is the distance of objects from each other or from a reference point. Distances are also calculated by data mining operations like k Nearest Neighbors.
Two different methods of calculating distances between points on the surface of Earth exist: Either we can pretend that the points are in a two-dimensional geometry with X and Y coordinates (which makes the distance calculation very easy), or we use the actual Earth ellipsoid for the calculation. The second method is very computing-intensive, but it returns more precise results when used on larger distances (e. g. places on different continents). For many operations acting on a limited area, the first method is used.
Transformation to another projection (coordinate system)
As described in the introduction, we often need to transform geometries to different projections so we can use units like meters. Coordinate system transformation is also available in GeoScript, and using it is quite easy.
import geoscript.proj.*;
//Source and destination projections
fromProj = new Projection("epsg:4326");
toProj = new Projection("epsg:3035");
projectedGeom = Projection.transform(geom, fromProj, toProj);
Here is a readily usable RapidMiner process. It takes three parameters that can be specified as macros in the process context. You can overwrite them when calling the process in the Execute Process operator.
GEOM_ATT: Name of the attribute that contains the geometry to be transformed (in WKT format)
FROM_PROJECTION, TO_PROJECTION: The EPSG numbers of the source and target projections
With this process, you can easily transform geometries from a common coordinate system like WGS84 (Latitude and Longitude, EPSG:4326) to a special one, for example ETRS89/Austria Lambert (EPSG:3416). We will use this in the example process for calculating distances between objects in Vienna, Austria and also determine the area and circumference of Vienna’s 23 districts.
Calculating distance, area and circumference
GeoScript contains easy to use functions:
area = geom.getArea();
circumference = geom.getLength();
//We need a second geometry for calculating distance
distance = geom1.distance(geom2);
After having transformed the geometry object into a matching projection, the calculations are really simple.
getArea() returns the area of a polygon or a group of polygons (Multipolygon); getLength() gives the length of a line or the circumference of a polygon in the units of the used projection.
For calculating the distance, a second geometry object is required. It doesn’t need to be a point: it’s also possible to calculate the distance between lines and areas.
The example process fetches two data sets from the Vienna Open Data Portal: Museums (points) and district borders (polygons). The process transforms then from latitude and longitude coordinates into a projection used in Austria. One script calculates the area and circumference of the districts using getArea() and getLength(). The original data set already contains these measures so we can easily check that they’re correct. (Small differences are the consequence of rounding the coordinates for CSV export.)
After that, the first district (Inner City) is selected and joined with the museum data set. The combined data set contains two geometries in a common projection, so we can calculate the distance between the museum and the Inner City. Points in the first district have a distance of 0.
Calculating distances on the surface of Earth
The second calculation method (more precise but slower) can also be used quite easily. For this, we import the class GeodeticCalculator from the GeoTools library, a base component of GeoScript. (The GeoScript libraries installed in the introduction are enough for this, we don’t need to set up more stuff.)
For using this method, we need latitude and longitudes of two points, in other words WGS84 coordinates. (It would be possible to use transformed coordinates by specifying a coordinate system in the GeodeticCalculator.)
Be careful when specifying the coordinates. We usually write X and Y coordinates in this order but GIS tools often use the order Y, X.
The example process contains coordinate pairs of a few capital cities lying on different continents. We build a Cartesian Product of all cities and calculate their distances in kilometers. (The distances were verified with PostGIS, they are very precise.) On these distances, using the geometry method would result in huge inaccuracies, so it’s really better to use the GeodeticCalculator method there.
Heute fand der zweite und damit letzte Tag der PRAN statt. Die Vorträge waren wieder sehr interessant.
Christoph Reininger von Runtastic sprach über die Methoden und Werkzeuge der Kunden-Analytik. Hier habe ich mir mehr erwartet. Im Vortrag ging es eher nur um klassische Kundensegmentierung und Customer Life Time Value, beides sind Dinge, die viele andere klassische Firmen machen. Aber wahrscheinlich wollen sie die wirklich innovativen Dinge (falls diese stattfinden) nicht an die große Glocke hängen. Es ist jedenfalls gut zu wissen, daß die von Runtastic direkt erhobenen Daten alle in Österreich in einem Rechenzentrum gespeichert sind und nicht irgendwo in der Cloud. (Leider gilt das nicht für die Google-Analytics-Daten und jene aus dem Werbenetzwerk.)
Marc Bastien von IBM demonstrierte dann IBM Watson Analytics. Das ist schon beeindruckend, wie viel Intelligenz in diesem Cloud-Werkzeug steckt. Aktuell kann es noch keinen Data Scientist ersetzen, aber wenn gerade kein solcher in der Nähe ist, könnte es helfen, in den eigenen Daten interessante Zusammenhänge zu entdecken. Hier kam schon vom Vortragenden die Empfehlung, keine personenbezogenen Daten hochzuladen – selten sind Cloud-Diensteanbieter so ehrlich, zuzugeben, daß es datenschutzrechtliche Bedenken gibt. (Generell wurde die gestrige EuGH-Entscheidung zum Safe-Harbor-Abkommen mehrmals thematisiert. Darüber wird es in nächster Zeit sicher noch einiges zu diskutieren geben.)
Allan Hanbury von der TU Wien zeigte medizinische Anwendungen von Big Data. Spannend für mich und andere im Publikum war die Erkenntnis, daß Ärzte lieber auf Google und Wikipedia nach Symptomen und Therapien suchen als in medizinischer Fachliteratur. Traurig ist auch, daß die Elektronische Gesundheitskarte ELGA zwar eine Zusammenführung der Daten erlaubt, aber Forschung mit ihnen explizit untersagt. Die Konsequenz daraus ist wohl ein opt out. Dafür gibt es im Bereich der Radiologie Fortschritte: Es wurde eine „Suchmaschine“ entwickelt, mit der Ärzte nach Auffälligkeiten in Röntgenbildern und den dazu gehörenden Diagnosen suchen können.
Lisa Neuhofer und Barbara Hachmöller von myr:conn solutions stellten ihr Projekt vor, das Erdölunternehmen hilft, die Ergiebigkeit einer Ölquelle anhand von Probebohrungen zu schätzen. Sie haben dafür einen recht erfolgreichen Modellierungsprozess entwickeln können. Die Anwendung zeigt auch wieder, wie weit das Feld ist, an dem man Analytik einsetzen kann. Bei diesem Thema war auch die Zusammenarbeit mit der Geowissenschaft (welche Gesteinsschichten welche Eigenschaften haben) sehr wichtig.
Nach der Mittagspause sprach Stefan Gindl von der Modul University über Herausforderungen und Trends der Stimmungsanalyse (sentiment analysis, ein Untergebiet von Text Mining). Es ist interessant zu sehen, daß die heutigen Ansätze bereits gut funktionieren, aber bei Themen wie der Erkennung von Sarkasmus und Ironie noch Verbesserungsbedarf besteht. Tatsächlich gibt es aber schon erste Fortschritte in der Forschung auf diesem Gebiet.
Jens Barthelmes von IBM schloß an. Sein Thema war „Social Media Analytics – Alles nur Hype?“. Er erwähnte verschiedene Kritikpunkte an den Datenquellen (die tatsächlich ziemlich chaotisch sind) und den Ergebnissen und erklärte, warum seiner Meinung nach trotzdem ein Wert in dieser Form der Analytik besteht. Das „Geheimnis“ ist, nicht nach der Phase „Monatsbericht über die Wahrnehmung des Unternehmens auf Facebook/Twitter/usw.“ aufzuhören, sondern die Ergebnisse als zusätzlichen Input für die restliche Analytik des Unternehmens anzusehen. Somit lassen sich etwa Absatzprognosemodelle etwas verbessern.
Michael Sedlmair von der Uni Wien sprach über Visualisierung im Big-Data-Zeitalter. Große Datensätze mit eventuell vielen Attributen lassen sich ja mit herkömmlichen Methoden schlecht darstellen. Für dieses Problem hat er einige mögliche Lösungen wie etwa die automatische Vorselektion „interessanter“ Attribute präsentiert. Er gab seinem Bedauern Ausdruck, daß noch kein fertiges Werkzeug existiert, mit dem diese Operationen ohne Programmierung ausgeführt werden könnten.
Wie immer beschloß Prof. Marcus Hudec die Konferenz mit einem seiner berühmten 100-Folien-Vorträge. Die Präsentation war von Anfang bis Ende fesselnd: er erklärte neue Trends wie Deep Learning und beschäftigte sich mit den Auswirkungen großer Datensätze auf die statistischen Eigenschaften von Modellen, die Konfidenzberechnung und innovative Sampling-Verfahren.
Wie immer waren es interessante anderthalb Tage bei der Konferenz. Ich nehme eine Menge Anregungen für meine Projekte in nächster Zeit mit und bin 2016 sicher wieder dabei.
Die Predictive-Analytics-Konferenz in Wien ist für mich jedes Jahr ein Pflichttermin. Die meisten Vorträge sind spannend und man trifft viele interessante Leute. In Wien ist es ja sonst nicht so einfach, Gesprächpartner mit Data-Mining-Erfahrung zu finden.
Die Keynote war ein sehr interessanter Vortrag von Stefan Stoll (Duale Hochschule Baden-Württemberg), der über disruptive Entwicklungen durch den Einsatz von Software und Analytik gesprochen hat. Er hat dabei wirtschaftliche Zusammenhänge beleuchtet, die mir so bisher unbekannt waren.
Danach stellte Prof. Erich Neuwirth (bei dem ich meine ersten Statistik-Vorlesungen hatte) seine Methode der Wahlhochrechnungen vor. Er gab auch historische Einblicke in die Anfangszeit in den 1970ern und erklärte den Kontrast mit heute: einerseits waren die Modelle damals einfacher, weil nur zwei Großparteien und eine kleine existierten, andererseits geschieht die Berechnung selbst heute in Sekunden auf einem PC, während damals Großrechner eingesetzt werden mußten.
Michael Wurst von IBM stellte die In-Database-Mining-Möglichkeiten der IBM-Datenbankprodukte vor. Es ist jetzt möglich, Data-Mining-Verfahren etwa in Netezza und DB/2 auszuführen, entweder native Implementierungen oder externe R- oder Python-Skripts. Analytik in der Datenbank ist für mich auch sehr interessant, ich habe dazu bereits 2014 bei den Linuxwochen vorgetragen und es wird auch bei den PostgreSQL-Konferenzen in Wien und Hamburg diesen Herbst mein Thema sein.
Ingo Feinerer stellt das von ihm entwickelte R-Paket „tm“ vor. Dieses Paket ist eine Komplettlösung für Text Mining in R. Dieses Aufgabengebiet habe ich bisher nur mit RapidMiner abgedeckt, aber ich werde sicher einmal auch die Gelegenheit haben, mit tm in R zu arbeiten. Spannend ist hierbei die transparente Hadoop-Integration, die ja für größere Textsammlungen notwendig sein kann.
Den Schlußvortrag des Tages hielten Wilfried Grossmann und Stefanie Rinderle-Ma von der Uni Wien. Sie berichteten über ihr Projekt, in einer Lernplattform an der Uni Process Mining zu betreiben. Soweit ich mich erinnern kann, war dies der erste Vortrag zu Business Process Mining bei der Predictive-Analytics-Konferenz. Das Thema ist sicher auch eine Betrachtung in SCO2T wert. Wenn der Tag nur mehr Stunden hätte…
… ist der Titel des Vortrags, den ich bei der Europäischen PostgreSQL-Konferenz eingereicht habe. Die Konferenz findet vom 27. bis 30. Oktober in Wien statt. Der Vortrag wurde vom Programmkomitee (alles große Namen in der PostgreSQL-Welt) angenommen.
Im Vortrag geht es um die verschiedenen Aufgaben im Bereich Data Science und wie PostgreSQL sie abdeckt:
Datenintegration und ETL: Foreign Data Wrappers für den Zugriff auf andere Datenbanken, Dateien, NoSQL- und Hadoop-Datenquellen; prozedurale Sprachen für den Zugriff auf Web-APIs und andere Systeme
Preprocessing: Standard-SQL und fortgeschrittene Methoden
Data understanding: Deskriptive Statistiken mit SQL, Visualisierung mit PL/R
Predictive analytics: Data Mining mit PL/R und PL/Python, Modellanwendung in der Datenbank
Ich freue mich sehr, vor dem hochkarätigen Publikum einer renommierten Konferenz über diese Themen sprechen zu können.
Die RapidMiner-Trainings in Dortmund erfreuen sich großer Beliebtheit und sind eine sehr gute Einführung ins Data Mining.
Leider ist Dortmund von Wien und Umgebung ziemlich weit entfernt. An- und Abreise verschlingen jeweils mindestens einen halben Tag, und dann kommen noch Kosten für die zusätzlichen Übernachtungen dazu.
Deswegen halte ich erstmals in Wien die Trainings „RapidMiner Basics“ Teil 1 und 2 ab.
Ingo Mierswa ist Gründer und Geschäftsführer von RapidMiner. In diesen Videos erklärt er Aspekte von Data science, Predictive analytics und Data mining. Ohne Formeln, aber mit viel Einhorn-Einsatz.
1. Folge: das Einhorn wird vorgestellt
2. Folge: die vier Aufgaben von Data mining
3. Folge: Der K-Nächste-Nachbarn-Algorithmus (Hinzugefügt: 2015-01-31)
4. Folge: Overfitting erklärt, und ein Gewinnspiel (Hinzugefügt: 2015-02-09)
5. Folge: Berechnung der zu erwartenden Ungenauigkeit prediktiver Modelle (Hinzugefügt: 2015-02-12)
Es kommen wöchentlich neue Folgen hinzu, hier ist die volle Playlist: