(English version)
jq ist ein Werkzeug zur Verarbeitung von JSON-Dokumenten. Es bietet Filter, Umformungen, Umstrukturierungen und andere Möglichkeiten, um die Dokumente in die gewünschte Form zu bringen.
Die JSON-Dokumente, mit denen man als Data Scientist zu tun hat, werden immer komplexer. Z. B. kommt von einer Web-API ein Dokument, das hierarchische, optionale Elemente enthält.
Für Data Mining braucht man jedoch immer eine tabellarische Struktur, ohne hierarchische Elemente und idealerweise auch ohne fehlende Daten. jq hilft dabei, die relevanten Teile der Eingangsdokumente in so eine Form zu bringen.
Nehmen wir folgendes simples Beispieldokument:
{
"count": 3,
"category": "example",
"elements": [
{
"id": 1,
"description": "first element",
"tags": ["tag1"]
},
{
"id": 2,
"description": "second element",
"optional": "optional element",
"tags": []
},
{
"id": 3,
"description": "third element",
"tags": ["tag1", "tag2"]
}
]
}
Wir sehen hier die üblichen Fallstricke komplexer JSON-Dokumente:
- Elemente auf unterschiedlichen Hierarchiestufen: category, elements/id usw.
- Optionale Elemente: elements[2]/optional
- Variable Anzahl von Elementen: elements/tags
jq bietet eine relativ einfache Syntax, um solche Konstrukte zu verarbeiten. Am einfachsten ist es, die Ausdrücke online bei jqplay.org zu entwickeln.
Vielleicht ist das Ziel, eine Tabelle mit category, der Element-Id und den Tags zu erstellen. Der jq-Ausdruck dafür lautet:
{count, category, elements: .elements[] } | {category, id: .elements.id, tag: .elements.tags[]}
Auf den ersten Blick etwas furchteinflößend, aber letztendlich aus einfachen Elementen aufgebaut. Wenn man den Ausdruck Schritt für Schritt bei jqplay ausführt, wird es klarer.
Im ersten Schritt (die Schritte sind mit dem Pipe-Symbol | getrennt) deklarieren wir, welche Elemente wir verarbeiten möchten. Dabei wird eine Liste von Objekten mit {} aufgebaut, darin count und category aus der Hauptebene des Dokuments, und die Elemente als Array. count und category werden dabei wiederholt, damit die „Tabelle“ vollständig ist.
Im zweiten Schritt selektieren wir die category (ursprünglich auf der Hauptebene) und die id jedes Objekts; dazu die Tags als Array. Mit name: .hauptelement.kindelement können wir Elemente selektieren und benennen. Das Ergebnis dieses Schrittes ist eine Liste von Objekten mit category, id, und tag in einer tabellarischen Struktur, die wir etwa in eine Datenbank schreiben oder in einem Data-Mining-Tool verarbeiten könnten.
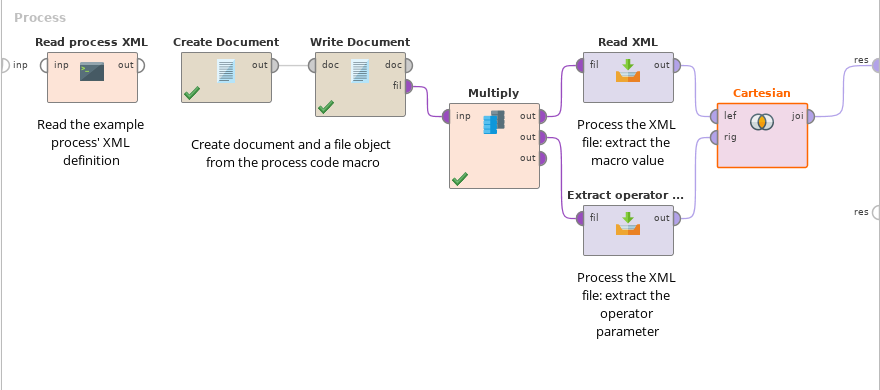
jq in RapidMiner
Um so komplexe Dokumente in RapidMiner verarbeiten zu können, wäre es praktisch, jq direkt einzubinden. Genau das habe ich gemacht, mit Hilfe von jackson-jq, einer Java-Implementierung.
Zur Vorbereitung müssen wir die Jar-Datei von jackson-jq und zwei Abhängigkeiten ins lib-Verzeichnis von RapidMiner Studio kopieren. Danach steht die Funktionalität im eingebauten Groovy Scripting Operator (Execute Script) zur Verfügung.
Um die Anwendung zu vereinfachen, habe ich zwei RapidMiner-Prozesse erstellt, die in eigenen Prozessen eingebunden werden können. Eine Variante arbeitet an Tabellen (Example Sets), hier muß man beim Aufruf festlegen, welches Attribut die Eingangsdaten enthält und wie das Zielattribut mit dem Ergebnis der Transformation heißen soll. Die andere Variante arbeitet an Document-Objekten, wie sie etwa von Get Page geliefert werden.
In beiden Fällen kann man noch den jq-Ausdruck angeben, festlegen, ob der Output eingerückt formatiert werden soll, und letztendlich wählen, ob das Ergebnis in CSV konvertiert werden soll. Das CSV-formatierte Ergebnis kann RapidMiner mit Read CSV sehr einfach in eine Tabelle umwandeln — das ist bei mir häufig das Ziel.
In jqplay würden wir für den CSV-Output noch folgendes anhängen, und „Raw Output“ auswählen:
| [ .category, .id, .tag ] | @csv
Damit erzeugen wir ein Array (mit der []-Syntax) und nennen die auszugebenden Elemente. Das Ergebnis wird dann mit @csv umformatiert. (Diesen letzten Schritt erledigt der RapidMiner-Prozess automatisch, wenn der CSV-Output ausgewählt ist.)
Mit etwas Üben und der Hilfe von jqplay lassen sich somit Prozesse erstellen, die aus einem verschachtelten JSON-Dokument relativ einfach eine gut handhabbare Tabelle erstellen.
Um verschiedene Hierarchien innerhalb des Dokuments zu verarbeiten, könnte man auch verschiedene jq-Ausdrücke anwenden, und daraus unterschiedliche Tabellen erhalten.
jq is a command line tool for processing JSON documents. It can filter, transform and restructure documents to format them in the way we want.
The JSON documents data scientists have to work with are becoming more and more complex. Web APIs often generate documents with hierarchic structure and optional elements.
Data mining, however, needs a tabular structure, without hierarchic elements, and if possible without missing data. jq helps us with the transformation of relevant parts of input documents into this shape.
Take the following example document:
{
"count": 3,
"category": "example",
"elements": [
{
"id": 1,
"description": "first element",
"tags": ["tag1"]
},
{
"id": 2,
"description": "second element",
"optional": "optional element",
"tags": []
},
{
"id": 3,
"description": "third element",
"tags": ["tag1", "tag2"]
}
]
}
This shows the usual pitfalls of complex JSON documents:
- Elements on different hierarchy levels: category, elements/id etc.
- Optional elements: elements[2]/optional
- Variable number of elements: elements/tags
The easiest way to try jq is online at jqplay.org.
We might want to create a table with the category, the element id and the tags. The jq expression for this is:
{count, category, elements: .elements[] } | {category, id: .elements.id, tag: .elements.tags[]}
Scary for sure in the first moment! But when you look at it, it’s built of simple elements. You can always execute it step by step at jqplay to see the effects of each step.
In the first step (the steps being delimited by the pipe symbol „|“) we declare the elements we want to process. We build an object list with { }, taking count and category from the top level and an array of the elements. count and category are repeated to create a proper table.
In the second step we select category and the object id-s, which were on different levels previously. The tags are selected as an array. Using the syntax name: .element.element we can select elements and name them. The result of this step is a list of objects having category, id and tag in a table, suitable for writing into a relational database or processing in a data mining tool.
jq in RapidMiner
It would be useful to process these kinds of documents with jq in RapidMiner. This is what I did, using jackson-jq, a Java implementation of jq.
To prepare, we need to copy the jackson-jq jar file and two dependencies into the RapidMiner Studio lib directory. Then we’re able to use the functionality in the built-in Groovy scripting operator (Execute Script).
I created two RapidMiner processes to make the application easier. These can be used in other processes. There is one variant working on tables (example sets), here you specify the name of the input attribute containing your documents and the target attribute for the transformation result. The other variant works on Document objects, like those coming from Get Page.
In both cases you specify the jq expression and set up the output options. You can indent the output, and convert the result to CSV. The CSV formatted result can be easily transformed to an example set — this is a frequent use case.
If you want to see CSV output in jqplay, check „Raw Output“ and append the following:
| [ .category, .id, .tag ] | @csv
This creates an array (with the [] syntax) and lists the elements in the output. The result is converted with the @csv step. (The RapidMiner process does this automatically if the csv output is selected.)
This, together with some practicing in jqplay, enables processes that can transform complex JSON documents to straight tables.
To process different parts and structures in the document, just multiply it and apply different jq expressions on the copies.