Die neue Custom-Operator-Erweiterung in RapidMiner beschäftigt mich weiter.
In den letzten Tagen habe ich zwei detaillierte Anleitungen in die RapidMiner-Community gestellt, um anderen die Entwicklung eigener Operatoren sowie die Arbeit mit der GeoProcessing-Extension zu vereinfachen:
The mesmerizing Custom Operators extension in RapidMiner is keeping me busy.
I put two detailed tutorials into the RapidMiner Community in order to make it easier for others to create their own operators and to start analyzing data with the GeoProcessing extension:
Ich habe früher beschrieben, wie geographische Joins und Filter in RapidMiner mit Hilfe des Cartesian-Product-Operators umgesetzt werden. Dieser Ansatz ist relativ einfach nachvollziehbar und funktioniert mit kleinen Datenmengen ganz gut.
Leider wird bei einem Cartesian Join jede Zeile der beiden hineingehenden Datensätze miteinander kombiniert. Das Ergebnis des kartesischen Produkts hat dann so viele Zeilen wie das Produkt der beiden Datensatzlängen. Natürlich wird da viel Speicher verwendet, und die Schleife mit den gewünschten Berechnungen läuft länger.
Für größere Datenmengen mit jeweils Hunderten oder Tausenden von Zeilen gibt es einen besseren Ansatz. Der Script-Operator kann auch zwei ExampleSets verarbeiten. Mit einem etwas komplexeren Skript kann der Prozess in einer verschachtelten Schleife beliebige Join-Kriterien anwenden, ohne den Speicher mit einem temporären kartesischen Produkt zu belasten.
In diesem Beispielprozess hole ich von Open Data Wien eine Liste von über 28.000 Straßenabschnitten in Wien (als Linien) sowie die 23 Wiener Bezirke (als Flächen). Die Aufgabe ist, für jeden Bezirk die Straßen zu bestimmen, die in ihm liegen. Dafür wird die GeoScript-Funktion contains() verwendet.
Bei der Cartesian-Join-Methode werden für jede Zeile zwei als String gespeicherte Geo-Objekte konvertiert. Dies ist aufwändig, aber kaum zu vermeiden. Mit der verbesserten Methode ist es einfach, ein Array von konvertierten Geo-Objekten zu erstellen und indexbasiert abzufragen.
Das Ergebnis ist ein Prozess, der mit relativ geringen Speicher-Anforderungen und einer akzeptablen Geschwindigkeit auch größere Datenmengen verknüpfen kann.
Der Nachteil ist ein etwas komplexeres Skript, das jedoch nach der ersten Entwicklung leicht an neue Anforderungen angepaßt werden kann.
Der größere Aufwand lohnt sich aber auf jeden Fall. Der Beispielprozess ordnet auf meinem Rechner die 28.309 Straßen den 23 Bezirken in ca. 14 Sekunden zu. Ein versuchsweise erstellter alternativer Prozess, der mit Cartesian Join arbeitet, läuft über 20 Minuten, also fast 90 mal langsamer, und braucht dabei natürlich deutlich mehr Speicher.
Das Skript erstellt ein komplett neues ExampleSet, das alle Attribute aus den beiden hereinkommenden ExampleSets übernimmt (doppelte Attributnamen sollten vorher korrigiert werden). Das Ergebnis enthält nur die Datensätze, auf die die Bedingung zutrifft, es ist kein nachgeschalteter Filter notwendig.
Um das Skript möglichst wiederverwendbar/flexibel zu machen, werden alle prozess-spezifischen Teile am Anfang als Variablen konfiguriert. Das sind einerseits die Namen der beteiligten Attribute, andererseits aber auch die Join-Funktion. Da Groovy sogenannte Closures (Funktionsvariablen) anbietet, können wir am Anfang des Skripts die verwendete Funktion eingeben – die hier konfigurierte Funktion wird später im Join verwendet.
Konkret sieht die Definition so aus:
def joinFunc = { a1, a2 -> a1.contains(a2) }
Das bedeutet: eine Funktionsvariable namens joinFunc mit den Parametern a1 und a2 erstellen. Hinter dem -> erscheint der Inhalt der Funktion, in diesem Fall der Aufruf a1.contains(a2). Der Rückgabewert sollte ein Boolean sein; beim Rückgabewert True werden die beteiligten Zeilen ins Ergebnis ausgegeben. Der fixe Teil des Skripts ruft dann irgendwo in der Schleife die Funktion mit joinFunc(a1, a2) auf.
Diese Konstruktion hilft uns, das Skript einfacher wiederzuverwenden: Sollten wir einmal statt contains() etwa intersects() benötigen, braucht nur der Konfigurationsblock geändert zu werden. Wir müssen nicht mehr nach dem Funktionsaufruf irgendwo in den Tiefen des Skripts zu suchen.
Earlier I described geographic joins and filters in RapidMiner. The processes used the Cartesian Product operator. This approach is quite simple and easy to understand, and it works well with smaller data sets.
Cartesian Join combines each row of the incoming tables. The result has as many rows as the number of rows of both data sets multiplied together. This uses a lot of memory and the loop that calculates the results takes longer.
There‘s a better approach for larger data sets with hundreds or thousands of rows. The Execute Script operator can work with two incoming ExampleSets. A slightly more complex script can use nested loops to apply almost arbitrary join criteria on the data, without filling the memory with the cartesian product.
This example process fetches over 28,000 street segments as lines and 23 districts of Vienna as polygons from the Vienna Open Data server. The task is finding the streets inside each district. So this is a join based on the GeoScript function contains().
The Cartesian Join needs to convert two strings to Geometry objects in each line of the combined data set. This is slow and hard to avoid. The improved method makes it easy to create an array of converted Geometry objects and use them for further lookups.
The resulting process uses less memory and has an acceptable runtime even with large inputs. This comes at the cost of a more complex script; however, it should be easy to change the script for future requirements.
The effort is really worth it. On my computer the example process joins 28,309 streets with 23 districts in about 14 seconds. A variant of the process that uses Cartesian Join runs for over 20 minutes (about 90 times slower) and uses a lot more memory.
The script creates a new ExampleSet that combines all attributes of both incoming ExampleSets. (If you have duplicate attribute names, rename them before sending the data to the script.) The result contains only records that match the condition, no additional filtering is necessary.
In order to make the script as reusable as possible, all process specific parts are configured at the top in variables. There are variables for the join attributes‘ names and also for the join function. Groovy offers so-called Closures (function variables), so we can specify the function to use in the configuration block. The configured function will be used for joining later in the loop.
This is how the definition looks like:
def joinFunc = { a1, a2 -> a1.contains(a2) }
Translated: create a function variable called joinFunc created with parameters a1 and a2. The body of the function is specified after ->, in this case a1.contains(a2). The return value of the function should be a Boolean – if the value is True, the current rows will be put into the result example set.
The fixed part of the script calls this function using joinFunc(a1, a2) later in the loop.
With this construction we can reuse the script easily: If we need intersects() instead of contains() at some point in the future, we just change it in the script configuration, without having to analyze and change the code below.
Wie schon einige Male halte ich wieder einen Vortrag bei den Linuxwochen Wien. Dieses Jahr heißt mein Thema „Citizen Data Science“.
Der Begriff „Citizen Data Scientist“ wurde von großen Beratungsfirmen geprägt. Sie verstehen darunter Mitarbeiter in Unternehmen, die keine Data-Scientist-Ausbildung haben, aber trotzdem analytisch arbeiten.
Ich möchte mich allerdings auf mein Verständnis von „Citizen“– wir alle, nicht unbedingt in einem Unternehmenskontext – konzentrieren.
Im Vortrag geht es darum, was man sich unter Data Science vorstellen kann, welche Werkzeuge und Methoden es gibt, und wie man mit frei verfügbarer Software Daten holen, zusammenführen, verarbeiten und analysieren kann.
Einige Themen: Open Data und Web-APIs; Datenbanken; Software für Analytik.
Nach der Artikelserie über GIS in RapidMiner Studio (1, 2, 3, 4) geht es nun darum, wie die erhaltenen Ergebnisse visualisiert werden können. In Studio sind die Möglichkeiten dafür ja ziemlich eingeschränkt: Punkt-Daten können noch halbwegs als Scatterplots angezeigt werden, aber für Linien und Flächen gibt es keine guten Methoden.
RapidMiner Server bietet aber mit den Webapps die Möglichkeit einer flexiblen Visualisierung durch die Einbindung von JavaScript.
Einbindung von GeoTools
Für die nachfolgende Vorgehensweise ist es nicht notwendig, den Server ähnlich wie Studio mit Geo-Libraries auszustatten. Wenn man jedoch die gleichen GIS-Funktionen wie in Studio verwenden will, kann es sinnvoll sein.
Ausgehend vom eingerichteten geoscript-Verzeichnis wie im ersten Teil der Anleitung werden die Jar-Bibliotheken aus diesem Verzeichnis in die EAR-Datei des Servers kopiert. Man braucht dazu ein Zip-Werkzeug, ich habe den Midnight Commander verwendet.
RapidMiner Server beenden
rapidminer-server/standalone/deployments/rapidminer-server-X.Y.Z.ear zur Sicherheit anderswo hinkopieren
Aus dem lib/-Verzeichnis die alte groovy-X.jar löschen und die neue aus der Studio-Installation hineinkopieren
Alle Jar-Dateien aus dem geoscript-Ordner der Studio-Installation auch in lib/ kopieren. Wenn eine Datei schon vorhanden ist, muß sie nicht überschrieben werden.
RapidMiner Server starten.
Danach sollten alle Prozesse mit GIS-Verarbeitung aus Studio auch am Server funktionieren.
Visualisierung in Webapps
Meine Wahl fiel auf die Leaflet-Library, da sie Open Source und gut dokumentiert ist. Da wir in RapidMiner keinen eigenen GIS-Datentyp haben und die bisherigen Prozesse die Geodaten als WKT (Well Known Text) verarbeiten, brauchen wir noch die Mapbox-Omnivore-Library. Diese konvertiert WKT-Daten in GeoJSON, das bevorzugte Format von Leaflet.
Vor der Erstellung des Webapps bauen wir einen Prozess in Studio, der die gewünschten Daten ausgibt. Ein Beispielprozess könnte vom Wiener Open-Data-Server die Bezirksgrenzen als CSV und Bevölkerungsstatistiken holen. Die Bezirke werden über ein gemeinsames Feld (NUTS-Id) verknüpft. Der Output des Prozesses ist eine Tabelle mit den Geodaten des Bezirks, ihrer Fläche, der Gesamtbevölkerung und der Bevölkerungsdichte. Für die Bevölkerungsdichte errechnen wir mit Generate Attributes die Anzahl der Personen pro Quadratkilometer und klassifizieren sie, indem wir verschiedenen Wertbereichen HTML-Farben in der #AABBCC-Notation zuweisen. Hier ist die eigene Kreativität gefragt.
Der Prozess wird auf den Server gelegt. Unter Processes/Services legen wir eine neue Eintragung an und nennen sie z. B. ViennaDistrictPopDensitySvc. Wir wählen als Datenquelle den vorhin angelegten Prozess und als Output Format JSON. Es ist sinnvoll, dieses Webservice als anonym/öffentlich aufzusetzen, um zusätzliche Paßworteingaben zu vermeiden.
In der neuen Webapplikation erzeugen wir eine Komponente vom Typ Text, und schalten „Use graphical editor“ ab. Danach geben wir den HTML- und JavaScript-Code ein.
Dieser Teil holt die Leaflet- und Omnivore-Komponenten und erzeugt ein Objekt, in das die Karte eingefügt werden kann. Im CSS wird die Höhe in Pixeln angegeben (z. B. 650px).
Danach starten wir mit <script language="JavaScript"> einen JavaScript-Block, der am Ende mit </script> geschlossen wird.
Hier erzeugen wir das Kartenobjekt mit einer OpenStreetMap-Hintergrundkarte. Die Initialisierungsparameter sind Längen- und Breitengrad der anfänglichen Position der Karte, die Zahl dahinter (11 in diesem Beispiel) die Zoom-Stufe.
Es gibt viele Tile-Server, man sollte die Nutzungsbedingungen prüfen und die Herkunftsangabe (attribution) entsprechend anpassen.
Daten des RapidMiner-Prozesses holen
var Httpreq = new XMLHttpRequest();
Httpreq.open("GET","/api/rest/public/process/ViennaDistrictPopDensitySvc?",false);
Httpreq.send(null);
var mapdata = JSON.parse(Httpreq.responseText);
Dieser Block holt vom lokalen (oder auch einem beliebigen anderen) RapidMiner Server die Daten des Prozesses im JSON-Format und legt sie im mapdata-Objekt ab. Die URL des Webservice kann hier angepaßt werden.
Anzeige der Geo-Objekte
for (i = 0; i < mapdata.length; i++) {
var district = omnivore.wkt.parse(mapdata[i].SHAPE);
district.addTo(map)
.bindPopup(mapdata[i].NAME + "
Population density: " + mapdata[i].POP_DENSITY)
.setStyle({color: mapdata[i].densityColor, weight: 2, fillOpacity: 0.3});
}
Hier verarbeiten wir die Ergebnisse des Prozesses in einer Schleife. Aus jeder Zeile wird die Form des Bezirks (Attribut SHAPE in den Beispieldaten) mit Hilfe von Omnivore konvertiert, und als neues Objekt zur Karte hinzugefügt. Mit .setStyle(...) ordnen wir die im Prozess erzeugte Farbabstufung (im Beispiel das densityColor-Attribut) zu. Als zusätzliche Information erzeugen wir mit .bindPopup(...) noch ein Popup-Fenster, das beim Klick auf einen Bezirk angezeigt wird und zusätzliche Informationen enthält.
Linien-Daten werden ganz ähnlich angezeigt und verarbeitet. Bei Punkt-Daten können verschiedene Marker definiert werden, bei Leaflet gibt es die Anleitung dazu.
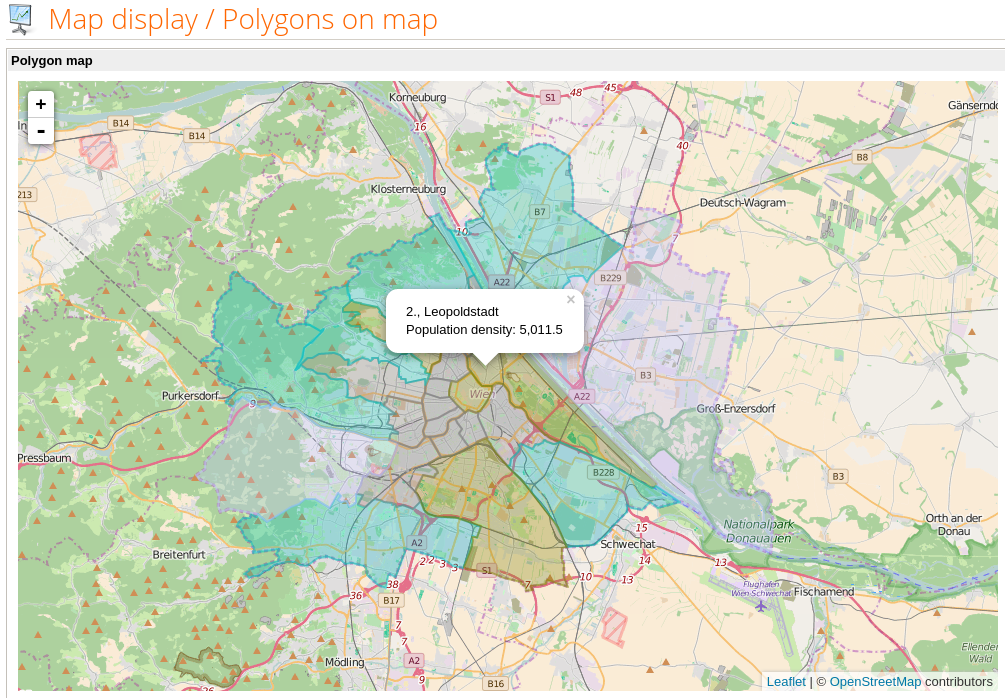
Damit ist das Ziel erreicht: RapidMiner Server zeigt eine Karte an, deren Daten (Punkte, Linien oder Flächen) in einen RapidMiner-Prozess verarbeitet wurden.
Bevölkerungsdichte pro Bezirk in Wien (Daten: Open Data Wien)
After the series of blog posts about GIS in RapidMiner Studio (1, 2, 3, 4) we’d probably like to visualize our results. The mechanisms in Studio are quite limited: we can create scatter plots from point data but there is no good method for displaying lines and areas.
However, RapidMiner Server offers webapps and powerful visualization using JavaScript.
Using GeoScript in processes
For displaying geographic data it’s not necessary to set up the server with the GeoScript libraries. However, if you want to execute the GIS processes like in studio, it can be a good idea to do so.
Start with the geoscript directory set up in the first part. You’ll need a Zip utility; I used Midnight Commander.
Stop RapidMiner Server
Make a backup copy of rapidminer-server/standalone/deployments/rapidminer-server-X.Y.Z.ear somewhere else
Delete the old groovy-X.jar from the lib/ directory and put in the new one from the Studio installation
Copy all jar files from the geoscript directory of the Studio installation to lib/. Existing files don’t need to be overwritten.
Start RapidMiner Server.
After this process, all your Studio GIS processes should work in the Server.
Map display in webapps
I chose the Leaflet library, as it is open source and well documented. There is no special GIS data type in RapidMiner and the processes in the tutorials used WKT (Well Known Text) until now, so we’ll also need the Mapbox Omnivore library. This converts WKT data to GeoJSON which Leaflet prefers.
Before starting with the web app, we need to build a process in Studio for creating the data. An example process could use the district boundaries as CSV and the population statistics from the Vienna Open Data server. It joins the districts using a common attribute (NUTS id). The output of the process is a table with the district boundaries, their area, the total population and the population density. We also use Generate Attributes to classify the population density with HTML colors (#AABBCC notation). You can get creative here and use the entire functionality of RapidMiner.
The process is saved on the server. We create a new entry in Processes/Services and call it for example ViennaDistrictPopDensitySvc. The data source is the process created before, the output format is JSON. It is a good idea to set up this web service for public anonymous access.
In a new web app we create a Text component and uncheck the „Use graphical editor“ checkbox to enter HTML and JavaScript code.
This part fetches the Leaflet and Omnivore components and creates a DIV object for the map. We specify the map height in pixels in the CSS block (e. g. 650px).
Then a JavaScript block is started with <script language="JavaScript">. Don’t forget to close the block with </script> at the end.
This creates a map object with an OpenStreetMap background layer. The initialization parameters are latitude and longitude of the initial position, and the zoom level (11 in this example).
There are many tile servers available. Be sure to check the terms of usage and update the attribution appropriately.
Getting data from the RapidMiner process
var Httpreq = new XMLHttpRequest();
Httpreq.open("GET","/api/rest/public/process/ViennaDistrictPopDensitySvc?",false);
Httpreq.send(null);
var mapdata = JSON.parse(Httpreq.responseText);
This part fetches the data in JSON format from the local RapidMiner Server and stores them in the mapdata variable. To refer to another web service, change the URL.
Displaying the objects on the map
for (i = 0; i < mapdata.length; i++) {
var district = omnivore.wkt.parse(mapdata[i].SHAPE);
district.addTo(map)
.bindPopup(mapdata[i].NAME + "
Population density: " + mapdata[i].POP_DENSITY)
.setStyle({color: mapdata[i].densityColor, weight: 2, fillOpacity: 0.3});
}
Here, a loop processes the process results. The Omnivore function converts the district area (SHAPE attribute in the example data) to a new object on the map. We assign the color calculated in the process with .setStyle(...) (densityColor attribute in this example). We also create a popup window with additional information using .bindPopup(...). It will be displayed when the user clicks a district.
Displaying line data is very similar. For displaying point data, you can use different markers. This is described by a Leaflet tutorial.
So we reached our goal: RapidMiner Server displays a map with data (points, lines or areas or even a combination) coming from a RapidMiner process.
Population density by district in Vienna (Data: Open Data Vienna)