Seit der Version 7.2 ist der RapidMiner Server in einer eingeschränkten Version frei erhältlich, und es lassen sich sehr nützliche Dinge damit machen.
Eine Kernfunktion ist das geplante Ausführen von Prozessen. Das passiert mit Hilfe von Cron-Ausdrücken, wobei die Implementierung in RM Server die Cron-Syntax vorne um ein Sekunden-Feld erweitert. Das erhöht natürlich die Flexibilität, aber birgt eine Gefahr in sich: wenn man nicht aufpaßt, legt man ganz schnell einen Cron-Job an, der jede Sekunde einen Prozess startet. Das kann auch den besten Server schnell in die Knie zwingen.
Leider ist die Benutzeroberfläche so gestaltet, daß die Standardeinstellungen genau dieses Problem verursachen:
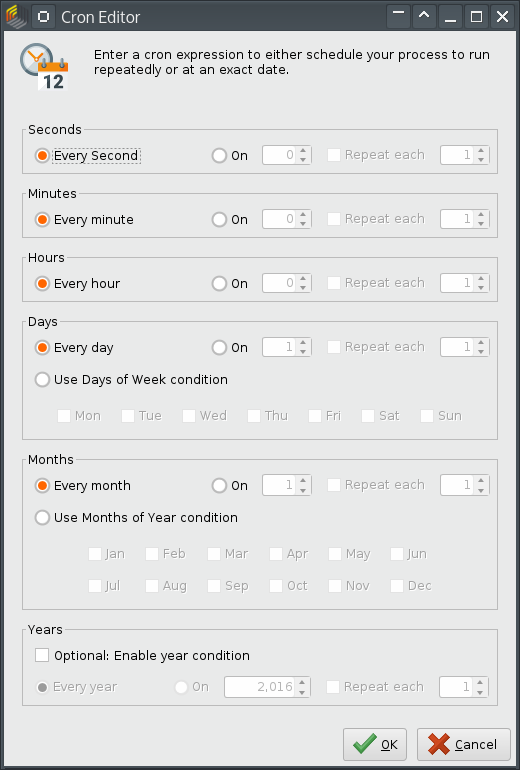
Wer intensiv an einem Server arbeitet, wird vielleicht früher oder später die Standardeinstellungen übernehmen. Oder es passiert jemandem in einem Training dieser Fehler. Glücklicherweise gibt es einen Weg, die Datenbank gegen diese Cron-Jobs abzusichern.
Mein RapidMiner Server verwendet eine PostgreSQL-Datenbank im Hintergrund. Die Tabelle qrtz_cron_triggers enthält die definierten Cron-Jobs. Es ist möglich, einen Trigger auf diese Tabelle zu legen, der unerwünschte Eingaben ablehnt oder, noch eleganter, korrigiert.
In PostgreSQL bestehen Trigger aus zwei Teilen: einer Triggerfunktion und dem eigentlichen Trigger. (Dadurch läßt sich eine Funktion für mehrere ähnliche Trigger verwenden, man muß sie nicht jedes Mal neu schreiben.)
Meine Triggerfunktion schaut so aus:
create or replace function check_second_cron() returns trigger
as $func$
begin
new.cron_expression = regexp_replace(new.cron_expression,
'^\s*(\*|\d+/\d)\s',
'0 ');
return new;
end;
$func$
language plpgsql;
Die Funktion ersetzt im hereinkommenden Cron-Ausdruck unerwünschte Sekundenangaben gegen 0. Eine unerwünschte Angabe ist * (jede Sekunde), die andere hat die Form X/Y (beginnend bei der Sekunde X, alle Y Sekunden). Hier vermeiden wir einstellige Sekundenangaben. Damit kann man einen Prozess alle 10 Sekunden oder seltener laufen lassen, aber nicht häufiger; das reduziert die Gefahr schon wesentlich.
Der reguläre Ausdruck schaut komplex aus, ist aber nicht so schlimm:
^\s* – Am Anfang darf Whitespace (Space oder Tabulator) vorkommen
(\*|\d+/\d) – Entweder ein Stern ODER Ziffer(n) gefolgt von einer Ziffer
\s – Wieder Whitespace
Der Trigger wird dann auf die Tabelle angewendet, und zwar sowohl bei Insert als auch bei Update, und auch nur, wenn der Cron-Ausdruck den unerwünschten Inhalt hat:
drop trigger if exists prevent_second_cron on qrtz_cron_triggers; create trigger prevent_second_cron before insert or update on qrtz_cron_triggers for each row when (new.cron_expression ~ '^\s*(\*|\d+/\d)\s') execute procedure check_second_cron();
Damit wurde der Server gegen die unabsichtliche oder bösartige Eingabe von zu häufig ausgeführten Cron-Prozessen abgesichert. (Natürlich könnte ein Angreifer auch anders viele Prozesse gleichzeitig starten; dagegen helfen nur Queues.)
Securing Cron in RapidMiner Server
A slightly limited version of RapidMiner Server is freely available since release 7.2. It is a very useful piece of software.
Scheduled process execution is a core functionality. The execution time and frequency are specified using Cron expressions; however, the implementation in RM Server extends the usual Cron syntax by a leading Seconds field. This gives us more flexibility but is also dangerous: If we aren’t careful, we can easily schedule a process to run every second. This can cause a huge usage even on the fastest server.
Unfortunately, the default settings in the user interface expose exactly this problem:
People working a lot on a server will probably accept the default values, or someone in a training makes a mistake. Fortunately, there’s a way to secure the database against this kind of Cron schedule.
My RapidMiner Server uses a PostgreSQL backend database. The table qrtz_cron_triggers contains the defined Cron jobs. It is easy to create a trigger on this table that rejects undesired input, or fixes it, which I consider more elegant.
Triggers consist of two parts in PostgreSQL: a trigger function and the actual trigger. (This allows us to use the same function in many triggers instead of writing it many times.)
This is my trigger function:
create or replace function check_second_cron() returns trigger
as $func$
begin
new.cron_expression = regexp_replace(new.cron_expression,
'^\s*(\*|\d+/\d)\s',
'0 ');
return new;
end;
$func$
language plpgsql;
The function replaces unwanted specification of seconds by zero. One kind of unwanted entry is * (every second), the other variant has the form X/Y (start at X seconds, repeat every Y seconds). Here we deny one-digit second entries. This allows us to schedule a process every 10 or more seconds, but not more frequently. This reduces the problem by a large margin.
The regular expression seems complex but it’s not too bad:
^\s* – The beginning of the expression can contain whitespace
(\*|\d+/\d) – A star OR digit(s) followed by / and one digit
\s – Whitespace again
The trigger is placed on the table both for Insert and Update and is executed when the expression has unwanted contents:
drop trigger if exists prevent_second_cron on qrtz_cron_triggers; create trigger prevent_second_cron before insert or update on qrtz_cron_triggers for each row when (new.cron_expression ~ '^\s*(\*|\d+/\d)\s') execute procedure check_second_cron();
Thus the server was secured against unintentional or malicious creation of Cron processes that run too often. (An attacker could start many processes at a time with other means, of course. This can be avoided with Queues.)