Window-Funktionen in RapidMiner
Richtige Datenbankserver wie PostgreSQL haben seit geraumer Zeit den SQL-99-Standard umgesetzt, der unter anderem Window Functions beschreibt.
Mit Window Functions lassen sich gruppenbezogene Statistiken und Kennzahlen berechnen, ohne die Ergebnismenge zu gruppieren. (Dies ist der Unterschied zur klassischen Aggregierung mit GROUP BY.) Es gibt eine Menge Anwendungsbeispiele: es lassen sich laufende Summen, gleitende Mittelwerte, Anteile innerhalb der Gruppe, gruppenweise Minima oder Maxima und noch viele andere Dinge berechnen. Manche Leute meinen, daß mit Window Functions eine neue Ära für SQL begonnen hat, und ich neige dazu, ihnen zuzustimmen.
RapidMiner hat bislang keine Window Functions eingebaut. Erfahrene Data Scientists, die Bedarf an dieser Funktionalität hatten, haben diese mit verschiedenen Operatoren (Loops, gruppenweise Aggregation und Join usw.) selbst nachbauen können, aber das ist alles andere als trivial.
Um die Funktionalität für einen größeren Benutzerkreis zu öffnen und gleichzeitig eine wiederverwendbare Implementierung zu schaffen, habe ich das Projekt rapidminer-windowfunctions ins Leben gerufen und eine erste funktionierende Implementierung hochgeladen.
Alle im RapidMiner-Operator „Aggregate“ eingebauten Aggregationsfunktionen lassen sich verwenden: sum, average, minimum, maximum usw. Zusätzlich sind die Funktionen row_number, rank und dense_rank verfügbar.
Im Projektordner sind der eigentliche Prozess und aktuell drei Beispielprozesse enthalten, um gleich verschiedene Anwendungsmöglichkeiten testen zu können.
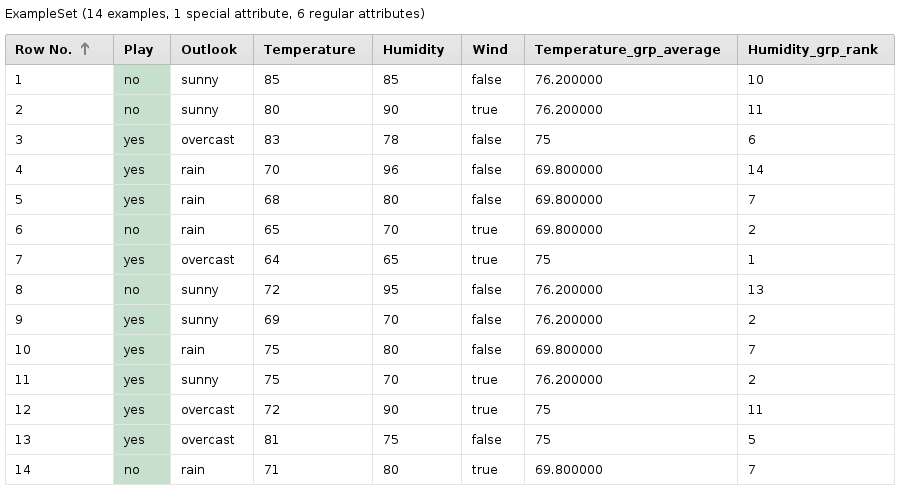
- Golf: Der berühmte Golf-Dataset wird aus dem mitgelieferten Beispiel-Repository geladen. Für jede Gruppe basierend auf dem „Outlook“-Attribut wird die Durchschnittstemperatur berechnet und als Attribut hinzugefügt. Ein zweites neues Attribut enthält den Rang des Datensatzes bei Sortierung nach dem Wert der Luftfeuchtigkeit. Gleiche Werte erhalten den gleichen Rang.
- Iris: Ein weiterer Standard-Dataset, Iris, wird geladen, und es wird pro Spezies der Durchschnittswert fürs Attribut „a3“ berechnet. Dieser Mittelwert wird dann genutzt, um Exemplare herauszufiltern, die mehr als 10 % vom Gruppenmittelwert entfernt sind.
- Deals: Der mitgelieferte Dataset „Deals“ wird geladen. In jeder Kundengruppe aus Geschlecht und Zahlungsmethode werden die drei ältesten Kunden gesucht, die anderen werden herausgefiltert.
Das zeigt schon die Bandbreite der Möglichkeiten, die Window Functions bieten. Die Möglichkeit, sie leicht einzusetzen und Indikatoren sowie Kennzahlen wie „Transaktionszähler des Kunden im Monat“, „Anteil des Produkts an der Monatssumme“ und ähnliche erzeugen zu können, wird viele Prozesse vereinfachen, oder neue Möglichkeiten eröffnen.
Implementierung
Nach einigen Prüfungen, z. B. ob die benötigten Makros gesetzt sind, werden neue Attribute zur Gruppierung und Identifizierung von Examples angelegt. Das zusammengesetzte Gruppierungsattribut wird dabei aus den Werten der als groupFields angegebenen Attribute generiert. Das Identifizerungs-Attribut muß mit einem Groovy-Skript generiert werden, da Generate Id mit vielen Datensätzen nicht funktionieren würde. (Generate Id funktioniert nicht, wenn der Datensatz bereits ein Attribut mit der Rolle id enthält.)
Die drei Spezialfunktionen, die in Aggregate nicht enthalten sind, werden gesondert behandelt. Die Untergruppen werden nach dem ausgewählten Attribut sortiert und der Datensatzzähler bzw. die Rangfolge berechnet.
Die Standard-Aggregierungsfunktionen von RapidMiner werden einfach auf jede Subgruppe angewendet, dabei entsteht jeweils eine gruppierte Zeile. Diese wird wieder mit den Originaldaten gejoint.
Einschränkungen
Gegenüber dem SQL-Standard und der in Datenbanken implementierten Funktionalität fehlt noch einiges. Z. B. erlauben Datenbanken bei Funktionen wie SUM die Angabe eines Sortierkriteriums und berechnen dann eine kumulierte Summe für jede Zeile, statt die gleiche Summe wiederholt auszugeben.
Der Prozess ist auch recht langsam, wenn viele Gruppen existieren. Dies ergibt eine große Anzahl von Filterungen in der Schleife. Bei den speziellen Rang- und Zählerfunktionen ist das Problem besonders ausgeprägt, da in jedem Durchlauf ein Groovy-Interpreter gestartet wird, was erhebliche Zeit kostet.
Das Konzept von Window-Definitionen geht in SQL-Datenbanken über Selektion von Gruppen hinaus. Z. B. kann man in SQL auf den vorherigen oder nächsten Datensatz zugreifen (LAG bzw. LEAD), ein fixes Fenster von X Zeilen definieren, und in den Daten „nach vorne“ schauen. Diese Dinge sind gegenwärtig nicht im Prozess eingebaut.
Mögliche Erweiterungen
Es spricht nichts dagegen, einige von den in SQL zur Verfügung stehenden Funktionen wie percent_rank, ntile oder first/last_value einzubauen. Dies wird bei Bedarf sicher passieren.
Die Funktionalität, über ORDER BY das Verhalten der Aggregierungsfunktionen zu ändern (z. B. für kumulierte Summen), erscheint mit RapidMiner-Mitteln nicht einfach. Allerdings ließe sich die kumulierte Summe leicht mit einem weiteren Groovy-Skript implementieren.
Bezugsquelle
Das Projekt kann auf Github heruntergeladen oder ausgecheckt werden. Es enthält Dokumentation und Beispielprozesse. Die Lizenz ist Apache 2.0, somit sind Einsatz und Weiterentwicklung uneingeschränkt möglich. Es ist also ein klassisches Open-Source-Projekt, das von der Beteiligung und Weiterentwicklung durch die Community leben soll.
Window functions in RapidMiner
For powerful database software like PostgreSQL the SQL-99 standard has been implemented for a long time. Window functions are an important part of SQL-99.
Window functions are used for calculating groupwise statistics and measures without actually grouping the result. (This is the difference between Window functions and the well-known aggregation with GROUP BY.) There are many applications: running sums, moving averages, ratios inside a group, groupwise minimum and maximum and so on. Some people consider the introduction of Window functions the beginning of a new era for SQL. I agree with this quite strongly.
RapidMiner doesn’t offer Window functions, yet. Experienced data scientists were able to build this functionality when they had to, using loops, aggregation and join, but these processes are not easy to create and debug.
My goal is to open this functionality for a larger group of potential users and to create a reusable implementation. So I started the rapidminer-windowfunctions project and uploaded the first working version.
All functions built into RapidMiner’s Aggregate operator can be used: sum, average, minimum, maximum etc. Additional functions are row_number, rank and dense_rank.
The project ships with the actual process and a number of example processes. These demonstrate different applications of Window functions on public datasets available in RapidMiner Studio.
-
Golf: The process loads the well-known Golf dataset from the Samples repository. For each group defined by the attribute “Outlook”, the average temperature gets calculated. A second attribute ranks the examples by the attribute “Humidity”. Identical values get the same rank.
-
Iris: This is another standard dataset, available from RapidMiner’s Samples repository. The process calculates the average value for the attribute “a3”. This group average is used to filter out examples which differ from the average by more than 10 %.
-
Deals: Another data set built into RapidMiner. This process considers all combinations of Gender and Payment Method as groups and ranks the customers based on their age. Only the 3 oldest customers per group are retained.
This is just a small sample of all the functionality available with Window Functions. Being able to use them easily for building indicators and measures like “transaction counter per customer and month” or “the product’s contribution percentage” will open new possibilities for modelling or reporting.
Implementation
The process checks a few preconditions, for example required parameter macros. It creates new attributes for grouping and identifying examples. The grouping attribute is built from all values given in the groupFields parameter. The identifying attribute needs to be generated in a Groovy script, as Generate Id would fail on too many real-world datasets. (It doesn’t work when the dataset already has an attribute with the role id.)
The three special functions not available in Aggregate are implemented with Groovy scripts. The process sorts the subgroups by the selected attributes and calculates the record counter or the rank.
The implementation of the standard aggregations is simpler: each subgroup is aggregated and the result is joined with the original data.
Limitations
Some functionality is missing compared to the SQL standard and to database systems. For example, in SQL databases, you can use ORDER BY in the window function to specify an ordering and calculate cumulative sums for each row instead of a groupwise sum.
The process is quite slow if many groups exist in the dataset. Having many groups results in a large number of filters in the loop. The performance is especially bad with the special ranking and counter functions because they start a Groovy interpreter in each iteration, which takes a lot of time compared to other operators.
The concept of window definition in SQL databases covers more than just the selection of groups. For example, you can access the previous and next records (LAG and LEAD), define a fixed window of N rows, and look forward in the data. These things are not available in the current version of the process.
Possible extensions
It’s entirely possible to implement more SQL standard functions like percent_rank, ntile and first/last_value. This will happen for sure when there’s a need.
It seems to be hard to change the behaviour of aggregation functions using ORDER BY (e. g. for cumulative sums) with RapidMiner means. However, special cases like the cumulative sum could be implemented with another Groovy script.
Getting the process
You can download the process or check it out on Github. The project also contains documentation and example processes. The license is Apache 2.0, so there are no restrictions on usage or further development. It is intended to become an Open Source project with the participation of and further development by the community.