Manchmal ist es am einfachsten, simple „Webanwendungen“ zur Dateneingabe mit den Pentaho-Dashboards zu entwickeln. (RapidMiner hat vor einiger Zeit ähnliche Funktionen in den Server eingebaut, um statt nur Dashboards echte Webapps entwickeln zu können.)
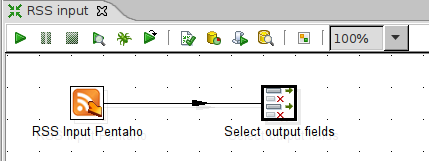
Eine wichtige Rolle spielt hierbei die Button-Komponente. Mit ihr kann man die Eingabe abschießen und z. B. mit einer Kettle-Transformation die Daten verarbeiten.
Normalerweise ist das Zusammenspiel zwischen Dashboard-Parametern, Komponenten-Parametern und Datenquellen-Parametern ziemlich simpel und logisch, aber in dieser Konstellation kann es kompliziert werden, insbesondere wenn die Dashboard-Parameter auch noch anders heißen als die Parameter der Transformation.
In diesem Beispiel legen wir die Simple Parameters Param1, Param2 und Parameter3 im Dashboard an, und in der PDI-Transformation die Parameter Param1, Param2 und Param3. Sie bekommen entsprechende Default-Werte, damit wir sie im Output unterscheiden können. Parameter3 ist im Dashboard absichtlich anders benannt.
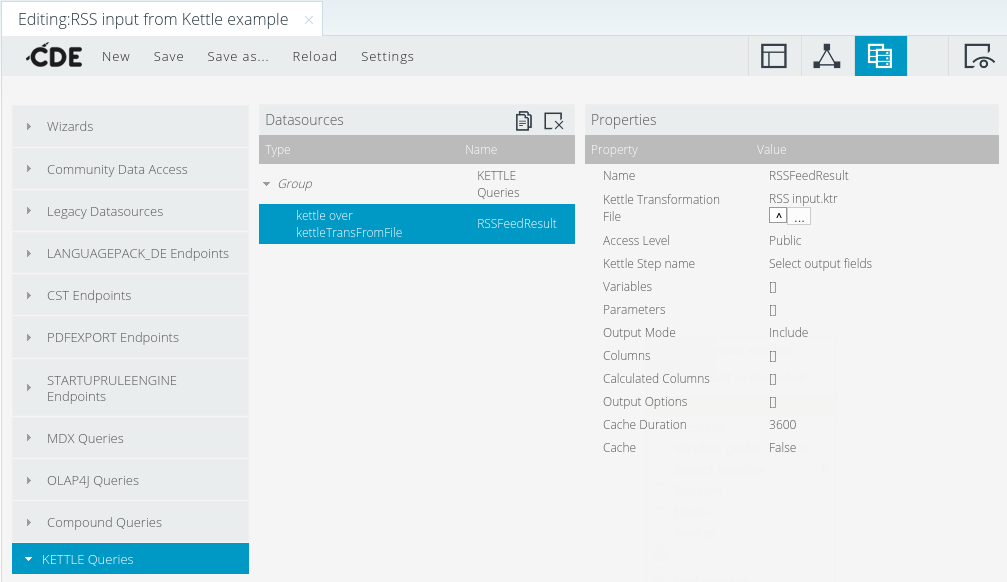
Wir legen eine Datenquelle vom Typ „kettle over kettleTransFromFile“ an und wählen die Transformationsdatei aus. Der Name eines Schrittes der Transformation wird unter „Kettle Step name“ festgelegt. Unter Variables geben wir die Namen der in der Transformation definierten Parameter (also Param1, Param2, Param3) ohne Value an (also bleiben alle Value-Felder leer). Unter Parameters wiederholen wir diese drei Namen, und als Value geben wir die gleichen Namen nochmal ein. (Also: Param1/Param1, Param2/Param2, Param3/Param3.)
Wichtig ist jetzt das korrekte Einstellen der Button-Komponente. Unter Advanced Properties wird zuerst „Action Datasource“ auf den Namen der Datenquelle gesetzt, und dann die Action Parameters eingegeben. Hier geben wir unter Arg die Parameternamen, die die Datenquelle erwartet, ein, also Param1, Param2 und Param3. Als Value aber die Namen der Dashboard-Parameter, also Param1, Param2 und Parameter3. Damit haben wir die Verbindung vom anders benannten Parameter zur Transformation geschaffen.
Pentaho Community Dashboards: The Button component and passing parameters
Sometimes, the easiest way to create a simple „data input web application“ is a Pentaho Dashboard. (RapidMiner put similar functionality into the Server to enable the development of web apps instead of only dashboards.)
The Button component has an important role when building applications: It is an easy way to take the input and call a Kettle transformation (for example) to process the data.
Usually, the interaction between Dashboard parameters, Component parameters and Datasource parameters is quite simple and logical. However, in this situation it can became more complicated, especially if the parameters in the dashboard and in the transformation have different names.
In this example, we create Simple Parameters called Param1, Param2 and Parameter3 in the dashboard, and Param1, Param2, Param3 in the PDI transformation. We assign them different default values so we can distinguish them in the output. Parameter3 is intentionally called differently in the dashboard.
We create the datasource of type „kettle over kettleTransFromFile“ and select the transformation file on the server. The name of one step in the transformation must be entered in „Kettle Step name“. In the Variables input, we enter the transformation parameter names Param1, Param2, Param3 without entering values. (The Value fields must stay empty.) In the Parameters, we enter the same names but this time also in the value fields: Param1/Param1, Param2/Param2, Param3/Param3.
Now it’s important to set up the Button component correctly. In the Advanced Properties, we set the Action Datasource to be the name of the data source, and then enter the Action Parameters. Here, the Arg names are the data source parameter names (Param1, Param2, Param3), and the Value names are the Dashboard parameter names: Param1, Param2 and Parameter3. This is how the link to differently named dashboard parameters is done.