Der Herbst dieses Jahres hält viele spannende Konferenzen bereit.
Gerade ist die Industrial Data Science 2017 in Dortmund zu Ende gegangen. Einen Tag lang hielten verschiedene Vertreter der Industrie hauptsächlich aus Deutschland interessante Vorträge über ihre Data-Science-Projekte. Es ging um komplexe Sachen wie die Vorhersage der Qualität von Stahl schon während des Verarbeitungsprozesses, von Engpässen in flexiblen Produktionsprozessen und um Produkt-Design mit automatischer Erstellung von Prozess- und Teilelisten. Die klassische Industrieanwendung „predictive maintenance“ haben diese führenden Unternehmen also bereits hinter sich. Allerdings wurden viele Projekte als noch nicht in Produktion befindlich angegeben – insofern liegt Österreich vielleicht noch gar nicht so weit zurück.
Das nächste Ereignis ist die Predictive-Analytics-Konferenz am 10. und 11. Oktober in Wien. Diese findet heuer schon zum 13. Mal statt, und ist jedes Jahr ein Pflichttermin für mich. Die Bandbreite der Vorträge in den letzten Jahren war sehr groß, und ich fand immer interessante Anregungen für meine Arbeit.
Weiter geht es dann zwischen 24. und 27. Oktober mit der Europäischen PostgreSQL-Konferenz, diesmal in Warschau. Hier werde ich über die erfolgreiche Migration der Mainframe-DB2-Datenbank nach PostgreSQL in München sprechen, und die Erfahrungen daraus.
Vom 10. bis 12. November findet dann das Pentaho-Community-Treffen in Mainz statt. Hier habe ich auch einen Vortrag eingereicht: Pentaho im Startup. Gemeint ist natürlich SCO2T. Auch wenn wir SCO2T mittlerweile nicht mehr als Startup, sondern als etabliertes Unternehmen und Marktführer bezeichnen, sind die Erfahrungen, die ich unter anderem mit Pentaho gemacht habe, hoffentlich fürs Publikum interessant. Da es schon zu viele technische Präsentationen gab, wurde ich gebeten, im Business-Track zu präsentieren, es werden also eher die Anwendungsfälle als die technischen Details zur Sprache kommen.
In this autumn, many interesting conferences present themselves to the data scientist.
The Industrial Data Science 2017 conference in Dortmund, Germany is already over. For an entire day, people from leading (mostly German) industry companies gave interesting talks about their data science projects. The topics were complex: predicting steel quality during the milling process, bottlenecks in flexible production processes and product design with automatic creation of process and parts lists. These companies are already well behind the basic industrial use case of predictive maintenance. However, many of the projects are still not in production – so companies in other countries didn‘t yet lost the race.
The next conference is Predictive Analytics in Vienna, with mostly German talks. This is the 13th iteration of the conference, and I always consider it a mandatory event for me. In the last years, the range of the topics was enormous, and I was always finding new approaches and ideas for my own work.
Still in October, the European PostgreSQL Conference will take place in Warsaw this time. There I‘ll present the successfull migration of a mainframe DB2 database to Postgres in Munich and the experiences I gained from this project.
In November, this year‘s Pentaho Community Meeting is in Mainz. I also submitted a talk there about Pentaho in a startup, with the startup being SCO2T, of course. We don‘t call SCO2T a startup anymore, but an established service provider and market leader. Still, the audience is hopefully interested in learning about the use cases with Pentaho in this environment. There were already too many technical presentations submitted, so I‘ll present in the business track. This means that the talk will be more about use cases than technical details.
Wenn man in einem Pentaho-System eine gewisse Anzahl von Dashboards und Berichten implementiert hat, ergibt sich unweigerlich die Frage nach der Navigation zwischen ihnen. Der eleganteste Weg ist ein zentrales Menüsystem, das leicht in alle Dashboards eingebunden werden kann und an einer Stelle verwaltet wird.
Das Bootstrap-Framework, das heutzutage in Pentaho Community Dashboards verwendet wird, bietet ein sogenanntes Navbar-Objekt, das für diese Zwecke sehr gut geeignet ist.
Für die beste Wartbarkeit erstellt man am besten eine eigene JavaScript-Datei, in der das Menü definiert wird. Diese Datei wird dann in allen Dashboards, die das Menü enthalten sollen, eingebunden.
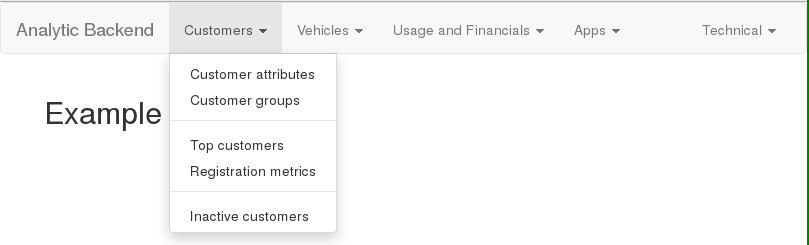
Die Menüzeile besteht aus einem Titel (im Beispiel „Analytic Backend“), der mit einem Link hinterlegt sein kann, und den einzelnen Menüs. Die Menüs enthalten die Menüpunkte (ebenfalls verlinkt) und Trennlinien.
Mit ein paar simplen JavaScript-Funktionen können alle benötigten Objekte als HTML-Code zusammengesetzt werden. Das fertige Navbar-Objekt wird dann in die Seite eingefügt.
Zuerst definieren wir die notwendigen Funktionen:
/*
Navigation menu for Pentaho Community Dashboards
*/
//Creates a menu item with a link
function menuLink(url, caption) {
return('<li><a href="' + url + '">' + caption + '</a></li>');
}
//Creates a separator item
function menuSeparator() {
return('<li role="separator" class="divider"></li>');
}
//Creates a drop-down menu with a title.
//If right = true, the menu will be right-aligned (this should be the last menu)
function menu(title, content, right) {
if (right === undefined) {
right = false;
}
if (right) {
rightClass = " navbar-right";
} else {
rightClass = "";
}
menuInit = '<ul class="nav navbar-nav' + rightClass + '"><li class="dropdown">' +
'<a href="#" class="dropdown-toggle" data-toggle="dropdown" role="button aria-haspopup="true" '+ 'aria-expanded="false">' + title + ' <span class="caret"></span></a>' +
'<ul class="dropdown-menu">';
menuEnd = '</ul></li></ul>';
return(menuInit + content + menuEnd);
}
//Creates the entire navigation bar
function menuNavbar(url, title, content) {
navbar = '<nav class="navbar navbar-default"><div class="container-fluid"><div class="navbar-header">' +
'<button type="button" class="navbar-toggle collapsed" data-toggle="collapse" data-target="#bs-example-navbar-collapse-1" aria-expanded="false">' +
'<span class="sr-only">Toggle navigation</span><span class="icon-bar"></span></button>' +
'<a class="navbar-brand" href="' + url + '">' + title + '</a></div>' +
'<div class="collapse navbar-collapse" id="mainMenu">' +
content +
'</div></div></nav>';
return(navbar);
}
Dann kommt der variable Teil, die Definition der Menüs und der Menüpunkte:
Die einzelnen menuLink-Zeilen enthalten die Ziel-URL (ein Dashboard, ein Report, oder auch eine beliebige URL außerhalb des Systems) und den Menü-Text.
Am Ende wird das Menü selbst angelegt.
//Concatenate menus in the desired order. If one is to be right-aligned, it must be the last one.
menuContent = customersMenu + vehiclesMenu +
usageFinancialsMenu + appsMenu + technicalMenu
;
//Create the navigation bar with a link, the main title and the whole menu content
navbar = menuNavbar("/pentaho/api/repos/%3Apublic%3AStart%20page.wcdf/generatedContent", "Analytic Backend", menuContent);
//When the document is ready, use JQuery to inject the navigation bar into the page content
$( document ).ready(function() {
$(".container").before(navbar);
});
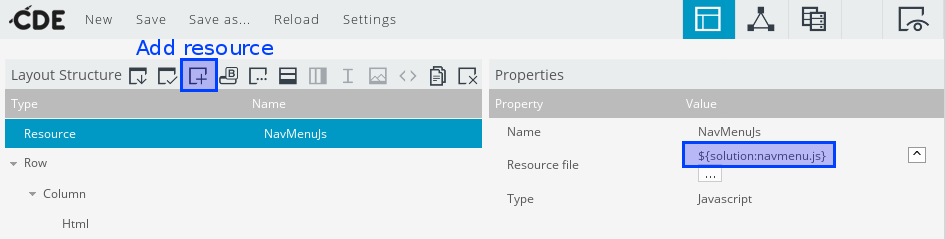
Damit haben wir die gewünschte Lösung: ein platzsparendes, zentral gewartetes Menü, das mit minimalem Aufwand in neue und bestehende Dashboards eingebaut werden kann: In der Layout-Ansicht „Add Resource“, type „JavaScript“, „External file“; dann wird die JavaScript-Datei im Dateibrowser ausgewählt oder einfach als Text eingefügt.
Navigation Menu for Pentaho Dashboards
When a Pentaho system reaches a certain number of dashboards and reports, the question of navigation between them becomes important. A central menu system an elegant way to solve this problem. It should be easy to include in dashboards and maintained in one place.
The Bootstrap framework used in Pentaho Community Dashboards, contains a Navbar object that is very suitable for this purpose.
For easy maintenance, a separate JavaScript file is created to define the menu. This file has to be included in all dashboards that need to contain the menu.
The navigation bar contains a title („Analytic Backend“ in the example) that can be linked to a URL, and the menus. The menus contain menu items (also with URLs) and separator lines.
A few simple JavaScript functions build the necessary HTML. The complete Navbar object is then inserted into the page.
First, a few functions:
/*
Navigation menu for Pentaho Community Dashboards
*/
//Creates a menu item with a link
function menuLink(url, caption) {
return('<li><a href="' + url + '">' + caption + '</a></li>');
}
//Creates a separator item
function menuSeparator() {
return('<li role="separator" class="divider"></li>');
}
//Creates a drop-down menu with a title.
//If right = true, the menu will be right-aligned (this should be the last menu)
function menu(title, content, right) {
if (right === undefined) {
right = false;
}
if (right) {
rightClass = " navbar-right";
} else {
rightClass = "";
}
menuInit = '<ul class="nav navbar-nav' + rightClass + '"><li class="dropdown">' +
'<a href="#" class="dropdown-toggle" data-toggle="dropdown" role="button aria-haspopup="true" '+ 'aria-expanded="false">' + title + ' <span class="caret"></span></a>' +
'<ul class="dropdown-menu">';
menuEnd = '</ul></li></ul>';
return(menuInit + content + menuEnd);
}
//Creates the entire navigation bar
function menuNavbar(url, title, content) {
navbar = '<nav class="navbar navbar-default"><div class="container-fluid"><div class="navbar-header">' +
'<button type="button" class="navbar-toggle collapsed" data-toggle="collapse" data-target="#bs-example-navbar-collapse-1" aria-expanded="false">' +
'<span class="sr-only">Toggle navigation</span><span class="icon-bar"></span></button>' +
'<a class="navbar-brand" href="' + url + '">' + title + '</a></div>' +
'<div class="collapse navbar-collapse" id="mainMenu">' +
content +
'</div></div></nav>';
return(navbar);
}
Then the variable part where the menus and menu items get defined:
All menuLink lines contain a target address (a dashboard or report in the Pentaho system or an external URL) and the menu text.
After the menus, the navigation bar itself is created.
//Concatenate menus in the desired order. If one is to be right-aligned, it must be the last one.
menuContent = customersMenu + vehiclesMenu +
usageFinancialsMenu + appsMenu + technicalMenu
;
//Create the navigation bar with a link, the main title and the whole menu content
navbar = menuNavbar("/pentaho/api/repos/%3Apublic%3AStart%20page.wcdf/generatedContent", "Analytic Backend", menuContent);
//When the document is ready, use JQuery to inject the navigation bar into the page content
$( document ).ready(function() {
$(".container").before(navbar);
});
This gives us the desired solution: a centrally maintained menu that can be easily built into dashboards.
In the Layout view click „Add Resource“ with the type JavaScript and External file. Select the file in the file browser or enter the file path.
Manchmal ist es am einfachsten, simple „Webanwendungen“ zur Dateneingabe mit den Pentaho-Dashboards zu entwickeln. (RapidMiner hat vor einiger Zeit ähnliche Funktionen in den Server eingebaut, um statt nur Dashboards echte Webapps entwickeln zu können.)
Eine wichtige Rolle spielt hierbei die Button-Komponente. Mit ihr kann man die Eingabe abschießen und z. B. mit einer Kettle-Transformation die Daten verarbeiten.
Normalerweise ist das Zusammenspiel zwischen Dashboard-Parametern, Komponenten-Parametern und Datenquellen-Parametern ziemlich simpel und logisch, aber in dieser Konstellation kann es kompliziert werden, insbesondere wenn die Dashboard-Parameter auch noch anders heißen als die Parameter der Transformation.
In diesem Beispiel legen wir die Simple Parameters Param1, Param2 und Parameter3 im Dashboard an, und in der PDI-Transformation die Parameter Param1, Param2 und Param3. Sie bekommen entsprechende Default-Werte, damit wir sie im Output unterscheiden können. Parameter3 ist im Dashboard absichtlich anders benannt.
Wir legen eine Datenquelle vom Typ „kettle over kettleTransFromFile“ an und wählen die Transformationsdatei aus. Der Name eines Schrittes der Transformation wird unter „Kettle Step name“ festgelegt. Unter Variables geben wir die Namen der in der Transformation definierten Parameter (also Param1, Param2, Param3) ohne Value an (also bleiben alle Value-Felder leer). Unter Parameters wiederholen wir diese drei Namen, und als Value geben wir die gleichen Namen nochmal ein. (Also: Param1/Param1, Param2/Param2, Param3/Param3.)
Wichtig ist jetzt das korrekte Einstellen der Button-Komponente. Unter Advanced Properties wird zuerst „Action Datasource“ auf den Namen der Datenquelle gesetzt, und dann die Action Parameters eingegeben. Hier geben wir unter Arg die Parameternamen, die die Datenquelle erwartet, ein, also Param1, Param2 und Param3. Als Value aber die Namen der Dashboard-Parameter, also Param1, Param2 und Parameter3. Damit haben wir die Verbindung vom anders benannten Parameter zur Transformation geschaffen.
Pentaho Community Dashboards: The Button component and passing parameters
Sometimes, the easiest way to create a simple „data input web application“ is a Pentaho Dashboard. (RapidMiner put similar functionality into the Server to enable the development of web apps instead of only dashboards.)
The Button component has an important role when building applications: It is an easy way to take the input and call a Kettle transformation (for example) to process the data.
Usually, the interaction between Dashboard parameters, Component parameters and Datasource parameters is quite simple and logical. However, in this situation it can became more complicated, especially if the parameters in the dashboard and in the transformation have different names.
In this example, we create Simple Parameters called Param1, Param2 and Parameter3 in the dashboard, and Param1, Param2, Param3 in the PDI transformation. We assign them different default values so we can distinguish them in the output. Parameter3 is intentionally called differently in the dashboard.
We create the datasource of type „kettle over kettleTransFromFile“ and select the transformation file on the server. The name of one step in the transformation must be entered in „Kettle Step name“. In the Variables input, we enter the transformation parameter names Param1, Param2, Param3 without entering values. (The Value fields must stay empty.) In the Parameters, we enter the same names but this time also in the value fields: Param1/Param1, Param2/Param2, Param3/Param3.
Now it’s important to set up the Button component correctly. In the Advanced Properties, we set the Action Datasource to be the name of the data source, and then enter the Action Parameters. Here, the Arg names are the data source parameter names (Param1, Param2, Param3), and the Value names are the Dashboard parameter names: Param1, Param2 and Parameter3. This is how the link to differently named dashboard parameters is done.
Im Pentaho BI Server ist eine sehr flexible Karten-Komponente enthalten, die leider nicht gerade ausführlich dokumentiert ist. Ich möchte hier eine kurze Anleitung für einen erfolgreichen Start geben.
Zuerst braucht man Positionsdaten. Diese liegen entweder als echte Geodaten (z. B. aus einer GIS-Datenbank wie PostGIS) oder als Breiten- und Längengrad (latitude/longitude) vor. Im Dashboard brauchen wir die lat/lon-Darstellung.
Als erstes legen wir im Layout-Panel des Dashboard-Editors einen Bereich für die Karte an, z. B. eine Zeile und darin eine Spalte, in diesem Beispiel mit einer Breite von 10 Elementen (Medium Devices). Diese Spalte benennen wir so, daß die Verbindung zum Map-Element erkennbar ist, z. B. MapDiv.
Datenquelle
Die Datenquelle für die Punkte auf der Karte definieren wir im Datasources Panel. Hier legen wir eine Abfrage namens MapQuery an, die uns die Geokoordinaten liefert. Diese Spalten müssen „Latitude“ und „Longitude“ heißen (die Klein- oder Großschreibung ist egal).
Hat man echte Geodaten in einer GIS-fähigen Datenbank, sind die Punkte eventuell in einer eigenen Spalte zusammengesetzt gespeichert. Das läßt sich leicht in die benötigten Koordinaten aufspalten:
SELECT ST_X(ST_Transform(geo, 4326)) as longitude,
ST_Y(ST_Transform(geo, 4326)) as latitude
FROM gis_table
In diesem Beispiel ist „geo“ der Name der Geodaten-Spalte. Mit ST_Transform(geo, 4326) konvertiert PostGIS die Koordinaten aus der in der Datenbank verwendeten Projektion in Länge- und Breitengrad. ST_X und ST_Y extrahieren aus dem konvertierten Objekt die einzelnen Koordinaten.
Karten-Komponente
Jetzt kann das Karten-Element im Components Panel angelegt werden: Custom: NewMapComponent.
Als Name wählen wir in diesem Beispiel einfach „Map“. Als Datasource tragen wir den Namen der Datenquelle (MapQuery) ein, und als HtmlObject den Namen des angelegten Bereichs (MapDiv).
Wenn wir das Dashboard speichern und ausführen, stellen wir fest, daß keine Karte angezeigt wird. Das liegt daran, daß die Karten im Gegensatz zu anderen Elementen selbst keinen Platz beanspruchen. Wir müssen also Breite und Höhe des enthaltenden Elements festlegen, entweder im Layout Panel mit Height, oder in einem Stylesheet.
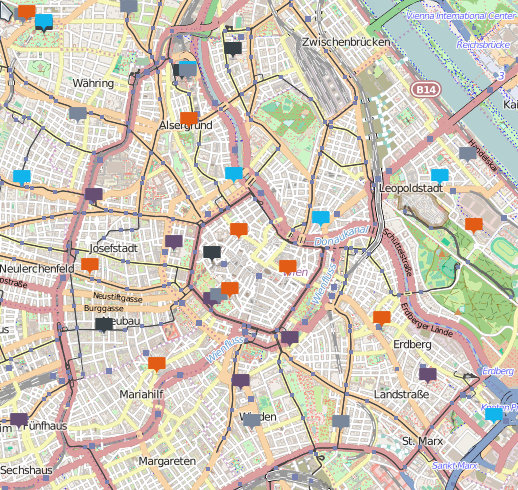
Das Ergebnis der Mühen ist eine Karte, in der die Punkte aus der Datenbankabfrage mit farbigen Standard-Symbolen markiert sind.
Büchereien in Wien – Kartendaten (c) OpenStreetMap contributors
Standardmäßig zeigt die Karte die ganze Erde an. Meist will man aber eine kleinere Region anzeigen. Das geht mit den Optionen Center Latitude und Center Longitude sowie Default Zoom Level.
Die beiden Center-Koordinaten kann man von der Karte ablesen, wenn man mit der Maus über sie fährt. Der Zoom Level hängt von der Größe der Kartendarstellung und dem darzustellenden Gebiet ab. Für eine Großstadt kann der Zoom ca. 12 betragen, Österreich paßt bei Zoom 7 ganz gut, Deutschland braucht schon Zoom 6.
Anpassung der Marker
Die Standard-Markierungen der Punkte auf der Karte passen nicht zu jeder Anwendung. Es besteht die Möglichkeit, eigene Symbole anzuzeigen: dazu gibt man in der Datenquelle die URL zum Symbol (ganz normale Bilddatei) in der Spalte „marker“ aus. Damit lassen sich zum Beispiel unterschiedliche Zustände der dargestellten Objekte anzeigen.
Popups
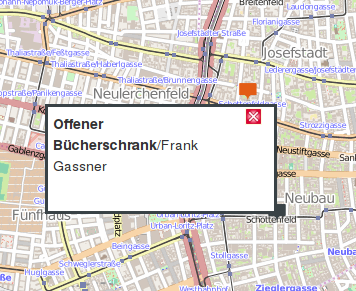
Zu jedem Marker können wir Zusatzinformationen anzeigen lassen. Wenn die Datenquelle eine Spalte „popupContents“ enthält, wird deren Inhalt (optional HTML-formatiert) angezeigt, wenn der Benutzer ein Marker-Symbol anklickt. Mit Popup Width und Popup Height läßt sich die Größe des Popups an den erwarteten Inhalt anpassen.
Beispiel eines formatierten Popups – Kartendaten (c) OpenStreetMap contributors
Mit diesen Optionen läßt sich schon ganz ohne Programmierung viel machen. Mit etwas JavaScript läßt sich noch viel mehr erreichen.
Automatische Aktualisierung der Karteninhalte
Im Gegensatz zu vielen anderen Dashboard-Komponenten bietet NewMapComponent keine Funktion zum automatischen Aktualisieren des Inhalts in festgelegten Abständen. In einigen Fällen möchte man jedoch die Positionen beweglicher Objekte darstellen und die Karte von Zeit zu Zeit automatisch aktualisieren. Glücklicherweise läßt sich das mit ein wenig JavaScript-Code erreichen.
In den Advanced Properties der Karten-Komponente geben wir in der Eigenschaft Post Execution eine Funktion ein:
//Sets up a timer to refresh the map after a minute
function () {
this.timerId = window.setTimeout(
function() {
render_Map.update();
}
, 60000);
}
60000 ist die Anzahl der Millisekunden, nach denen der Timer laufen soll. render_Map ist der Name der Karten-Komponente, mit „render_“ davor – so benennt das Community Dashboard Framework das JavaScript-Objekt.
Da diese Funktion immer nach dem Aktualisieren der Karte ausgeführt wird, ist gleich der nächste Timer nach der gleichen Periode aktiviert. Die Timer-ID, die in JavaScript zum Abbrechen des Timer genutzt werden kann, wird dabei im render_Map-Objekt gespeichert.
Es gibt nur ein Problem: Verschiebt der Benutzer den Kartenausschnitt oder zoomt hinein oder hinaus, setzt die Aktualisierung der Karte den Ausschnitt und den Zoom-Wert auf die Standardwerte. Die Karte kehrt also zum Ausgangspunkt zurück. Um das zu vermeiden, können wir vor dem Update noch schnell die aktuelle Sicht abspeichern, wodurch die Karte nicht mehr springt.
Folgende Funktion gehört in die Pre Execution-Eigenschaft:
//Before reloading the map automatically, save the current zoom level and position
function () {
if (this.timerId != null) {
//Get current map center and zoom level
center = this.mapEngine.map.center;
zoom = this.mapEngine.map.zoom;
//Transform to WGS84 coordinates
center.transform(this.mapEngine.map.projection, "EPSG:4326");
this.defaultZoomLevel = zoom;
this.centerLongitude = center.lon;
this.centerLatitude = center.lat;
}
}
Zuerst überprüfen wir, ob die timerId schon gesetzt ist. Beim ersten Anzeigen der Karte (wenn das Dashboards geöffnet wird) ist das noch nicht der Fall.
Ist die Karte schon fertig dargestellt worden, ist timerId beim nächsten Durchlauf nicht mehr leer, dann können wir also die Position und den Zoom-Level der Karte abfragen und in die Standardeinstellung der Komponente hineinschreiben.
Bei der nächsten automatischen Aktualisierung der Karte tritt zwar ein systembedingtes Flackern auf, aber der vom Benutzer gewählte Bildausschnitt bleibt bestehen.
Die Map-Komponente bietet noch andere Möglichkeiten, so wie das Thema der GIS-Daten ein fast unerschöpfliches ist. Ich werde sicher noch weitere Beiträge in diesem Themenkreis schreiben.
Displaying maps with the Pentaho Dashboard Framework
Pentaho BI Server contains a map component that’s very versatile but unfortunately quite sparsely documented. I’d like to give you a simple introduction into using the component.
First, we need position data. These are either stored in a real geographic database like PostGIS or separated into latitude and longitude. The dashboard map needs the lat/lon form.
First we create an area for the map in the Layout Panel of the Dashboard Editor. This can be a row and a column in it, for example with a width of 10 elements (enter it in the Medium Devices setting). We name this column MapDiv to state that it belongs to the map.
Data source
We need to specify the data source of the points in the Datasources Panel. Here, we enter a query called MapQuery that returns the coordinates. The columns must be called „Latitude“ and „Longitude“ (capitalization doesn’t matter).
Geograpic data in a GIS-capable database stores the points in a single column. It is easy to separate the two coordinates:
SELECT ST_X(ST_Transform(geo, 4326)) as longitude,
ST_Y(ST_Transform(geo, 4326)) as latitude
FROM gis_table
In this example, „geo“ is the name of the geodata column. In PostGIS, ST_Transform(geo, 4326) converts the coordinates from the geographic reference system used in the database to the classic Earth latitude and longitude values. ST_X and ST_Y extract the longitude and latitude from the compound object.
Map component
Now we create the Map element in the Components Panel by adding a Custom: NewMapComponent.
The name is simply „Map“ in this example. The Datasource is the name of our data source (MapQuery) and the HtmlObject is the name of the created row (MapDiv).
After saving and executing the dashboard, no map is shown. The reason is that the Map component itself doesn’t specify a content height, as other components do. So we need to set the width and height ourselves, either in the Layout Panel (Row Height) or in a stylesheet.
The result is a map that visualizes points from the database query with standard symbols in different colors.
By default, the map shows the entire Earth. We usually want to restrict the displayed area: this is done with the options Center Latitude/Longitude and Default Zoom Level.
The Center coordinates are displayed on the map when moving the mouse over it. The zoom level depends on the size of the map and the area to be shown. For a large city, the zoom can be around 12, Austria fits well with zoom = 7, and Germany requires zoom = 6.
Changing the markers
The default markers of map points aren’t suitable for some requirements. It is possible to use our own symbols: just return the URL of the symbol (a normal image file) in the column called „marker“ in the map data source. This allows us to visualize different object states.
Popups
For each marker we can display additional information in a popup area. If the data source contains a column named „popupContents“, its text (optionally HTML formatted) is displayed when the user clicks on a marker symbol. Popup Width and Popup Height can be changed to match the size of the content to display.
Using these options, we can already do a lot, entirely without programming. A bit of JavaScript can do a lot more.
Periodic updates of the map contents
In contrast to many other dashboard components, the NewMapComponent doesn’t have a setting for periodic updates. Sometimes we have to visualize objects that can move and automatically refresh the map from time to time. Fortunately, only a few lines of simple JavaScript are necessary to achieve this.
We enter the following function in the Advanced Properties of the Map component, in the property Post Execution:
//Sets up a timer to refresh the map after a minute
function () {
this.timerId = window.setTimeout(
function() {
render_Map.update();
}
, 60000);
}
60000 is the number of milliseconds after the timer executes the function. The map component is named render_Map in this example: the Community Dashboard Framework always prefixes the specified names with „render_“ to create the JavaScript object in the running dashboard.
This function is executed after each update of the map, so it also sets up the next automatic update after the same period. The timer ID stored in the render_Map object could be used to cancel the timer if desired.
However, there’s one usability problem: If the user moves the map or zooms in, the automatic update resets the map to the values defined in the dashboard properties and the map returns to the initial view. We can avoid this by storing the properties of the current view before the map update, so the map doesn’t jump around anymore.
The following function is entered into the Pre Execution property:
//Before reloading the map automatically, save the current zoom level and position
function () {
if (this.timerId != null) {
//Get current map center and zoom level
center = this.mapEngine.map.center;
zoom = this.mapEngine.map.zoom;
//Transform to WGS84 coordinates
center.transform(this.mapEngine.map.projection, "EPSG:4326");
this.defaultZoomLevel = zoom;
this.centerLongitude = center.lon;
this.centerLatitude = center.lat;
}
}
The function checks if the timerId is set. If the map is displayed the first time (when opening the dashboard), this is not yet the case.
In a map that is already displayed, the timerId has a value, so we can store the map’s position and zoom level in the properties of the map object.
The map update causes a visible flicker of the dashboard, but at least the map area selected by the user stays as it is.
The map component offers a lot more, and GIS data is an almost infinite topic. This blog post isn’t the last one about maps, that’s for sure.
Ein- bis zweimal im Jahr erscheint eine neue Version der Pentaho-Software mit sinnvollen Neuigkeiten, die man gerne auf den eigenen Servern anwenden möchte. Die Art des Releases (Programm, Daten und Konfiguration gemischt) ist zwar für einen schnellen Start mit der Software gut geeignet, aber ein Update auf die neue Version kann schwierig sein, wenn man die Konfiguration am Anfang nicht sauber herausgetrennt hat.
Mein Ansatz dazu ist folgender:
Im Hauptverzeichnis (z. B. /opt/pentaho) liegen die Verzeichnisse des Servers mit Versionierung (z. B. biserver-ce-5.3). Zusätzlich die Verzeichnisse configuration, repository und jdbc.
Die aktuell in Produktion verwendete Version wird ohne Versionsnummer (biserver-ce) verlinkt. Somit verweist der Startskript immer auf den richtigen Server, und bei Problemen mit einer neuen Version könnte man leicht zur älteren zurückkehren.
Diese Lösung erleichtert den Umstieg auf eine neue Version und verringert die Backup-Datenmenge (von 600 MB auf einige KB), weil die biserver-ce-Verzeichnisse nicht mitgesichert werden müssen, da nichts an eigener Arbeit in ihnen liegt.
Repository
Die aktuellen Releases des BI-Servers verwenden ein Jackrabbit-File-Repository in biserver-ce/pentaho-solutions/system/jackrabbit. Hierin liegt die Konfigurationsdatei sowie das Verzeichnis „repository“, das ich wie beschrieben ins Pentaho-Verzeichnis (raus aus der biserver-ce-Verzeichnisstruktur) verschiebe und mit einem Symlink verlinke. Vor einem Update auf eine neue Pentaho-Version sollte man dieses Verzeichnis zusätzlich sichern, da eine neuere Jackrabbit-Version ein neues Format einführen könnte, das mit älteren Versionen inkompatibel ist.
Zusätzlich deaktiviere ich in tomcat/webapps/pentaho/WEB-INF/web.xml den Start der hibernate- und quartz-Datenbanken mit HSQLDB. Die Sampledata-Datenbank wird von mitgelieferten Komponenten des Servers benötigt und bleibt daher aktiviert, in der vom Server mitgelieferten Version.
Diese vier Konfigurationsdateien gehören auch ins herausgelöste Konfigurationsverzeichnis verschoben und aus dem Server verlinkt. Die Dateien in pentaho-solutions können auch mit Symlinks verbunden werden, jene in Tomcat müssen aber Hardlinks sein.
Anpassung des Login-Fensters
Im Produktivbetrieb hat man die Default-Paßwörter geändert und die mitgelieferten User deaktiviert oder gelöscht. Deswegen ist die standardmäßig eingeschaltete Möglichkeit, als User oder Admin mit einem voreingestellten Paßwort einzuloggen, nicht mehr notwendig.
Das läßt sich in pentaho-solutions/system/pentaho.xml abschalten (login-show-users-list, login-show-sample-users).
Zusätzlich kann man das Login-Fenster mit Änderungen am mitgelieferten Stylesheet (pentaho-solutions/system/common-ui/resources/themes/crystal/globalCrystal.css) an die eigenen Vorstellungen anpassen.
Update strategy for Pentaho BI Server
Pentaho releases one or two new versions of their open source software each year, with interesting new functionality or bugfixes. The way the release is done is well suited for a new evaluation installation, but updating to the new version can be difficult if one didn’t separate out the configuration after the setup.
This is my approach to solving the issue:
There’s a main directory (e.g. /opt/pentaho). In it, the BI server’s files are unzipped and versioned (e. g. biserver-ce-5.3). In addition to the server directories, there’s also configuration, repository and jdbc.
The current production version is symlinked without a version number (e. g. biserver-ce). This causes the start script to always point to the correct server, but switching versions is still easy if necessary.
With this solution, it’s much easier to update to a new version. Backups are much smaller, only the few kilobytes of the configuration instead of the whole BI server (600 MB).
Repository
Current releases of Pentaho BI Server use a Jackrabbit file repository which is in biserver-ce/pentaho-solutions/system/jackrabbit. In this directory there’s a configuration file and a „repository“ directory which gets moved into the main Pentaho directory (out of the biserver-ce structure) and symlinked in „jackrabbit“. It’s a good idea to backup this directory before updating to a new release as Jackrabbit could possibly update the format so that it’s not compatible with older Pentaho releases anymore.
Database configuration
If you changed your database configuration from HSQLDB to another database, the following files are to be moved into configuration:
In addition, in tomcat/webapps/pentaho/WEB-INF/web.xml I deactivated the hibernate and quartz HSQL databases. The sampledata database is required by some components of the server, so I keep it active.
When moving these files into the separate config directory, be careful when linking. Tomcat doesn’t like symlinks so they need to be hardlinked.
Changing the login screen
On a production system the default passwords are hopefully changed and the sample users are deactivated or removed. So the default mechanism for logging as user or Admin in with predefined passwords is not necessary anymore.
This can be switched off in pentaho-solutions/system/pentaho.xml (login-show-users-list, login-show-sample-users).
In addition, the login screen can be further customized by changing the stylesheet (pentaho-solutions/system/common-ui/resources/themes/crystal/globalCrystal.css) for your own requirements.
(English version)
Komplexe Lösungen bestehen häufig aus mehr als einer Datenbank, manchmal sogar unterschiedlichen Typs. Im Fall von Sco2t haben wir eine „geerbte“ MySQL-Datenbank, während neue Daten wegen der erweiterten GIS-Funktionalität in PostgreSQL liegen. Natürlich müssen gewisse Daten zwischen beiden Systemen synchronisiert werden.
Pentaho Data Integration ist dafür eine sehr gute Lösung und wird auch intensiv verwendet. Allerdings möchte ich in einigen Fällen sofort auf Änderungen reagieren und nicht erst eine Minute später. (Und auch nicht ständig Java-Prozesse starten, die die meiste Zeit keine Änderungen finden.) Dafür bieten sich PostgreSQL-seitig Trigger an, die Änderungen an einer Tabelle in der MySQL-Datenbank nachvollziehen.
PostgreSQL 9.1 hat die erste Version der Foreign Data Wrappers genannten Funktionalität bekommen, seit 9.3 können diese sogar in fremde Datenbanken schreiben. Ein FDW-Modul für den Zugriff auf andere PostgreSQL-Server ist in 9.4 im PostgreSQL-Contrib-Bereich dabei, Module für viele andere Datenbanken (auch NoSQL und Hadoop!) sind verfügbar.
(Linked Server sind schon seit Längerem in vielen Datenbanksystemen verfügbar, PostgreSQL hatte dafür „dblink“. Diese Funktionalität hat sich aber großteils auf Verbindungen zum eigenen Datenbanktyp beschränkt.)
EnterpriseDB hat ein FDW-Modul für MySQL realisiert. Derzeit muß man es selbst kompilieren, da in den üblichen Repositories keine fertigen Pakete enthalten sind. Das ist aber nicht schwierig.
Installation auf einem Debian-System:
git clone https://github.com/EnterpriseDB/mysql_fdw.git
apt-get install make gcc libmysqlclient-dev postgresql-server-dev-9.4
cd mysql_fdw
make USE_PGXS=1
make USE_PGXS=1 install
Damit ist das Modul übersetzt und als PostgreSQL-Extension installiert. Der Rest passiert als PostgreSQL-User mit Superuser-Rechten in SQL:
CREATE EXTENSION mysql_fdw;
CREATE SERVER mysql_server FOREIGN DATA WRAPPER mysql_fdw
OPTIONS (host '127.0.0.1', port '3306');
CREATE USER MAPPING FOR username SERVER mysql_server
OPTIONS (username 'myuser', password 'mypassword');
CREATE FOREIGN TABLE mysqltabelle (
-- Felder aus der MySQL-Tabelle mit ihrem Datentyp
)
SERVER mysql_server
OPTIONS (dbname='datenbankname', table_name='OriginalTabelleName');
Damit ist die Fremdtabelle „mysqltabelle“ in der PostgreSQL-Datenbank angelegt und kann wie eine normale Tabelle angesprochen, gelesen und beschrieben werden.
CREATE EXTENSION registriert das Modul in der aktuellen Datenbank. (Verwendet man mehrere Datenbanken auf einem Server, muß CREATE EXTENSION in jeder, die die Funktionalität braucht, ausgeführt werden.)
CREATE SERVER erzeugt die Verbindung zum fremden Datenbankserver und gibt die Verbindungsparameter an.
CREATE USER MAPPING ist notwendig, um PostgreSQL-seitige User mit einem User in der fremden Datenbank zu verknüpfen. Es können mehrere Mappings für unterschiedliche User angelegt werden.
CREATE FOREIGN TABLE definiert dann die Fremdtabelle und gibt ihren Namen in der fremden Datenbank an. Die Datentypen der Felder müssen in PostgreSQL existieren. Es ist möglich, Constraints wie NOT NULL oder Default-Werte schon PostgreSQL-seitig anzugeben.
Foreign Tables eröffnen ganz neue Möglichkeiten der Datenintegration: Daten müssen nicht mehr hin und her kopiert werden, stattdessen sind sie in der Master-Datenbank und die anderen Datenbanken arbeiten immer mit der aktuellen Kopie. Datenübernahmeprozesse können direkt in der Datenbank, ohne Zwischenschaltung einer ETL-Software ausgeführt werden. Ich bin gespannt, welche Anwendungsmöglichkeiten mir noch einfallen.
Accessing foreign databases in PostgreSQL
Many complex solutions use more than one database, sometimes even different database systems. At Sco2t we „inherited“ a MySQL database, but new data are stored in PostgreSQL because of the better GIS functionality. So some data need to be kept in sync between the two systems.
Pentaho Data Integration is a great solution for this and it’s already in heavy use. In some situations, however, I’d like to react to changes instantly instead of waiting a minute. (Also, I dont’t want to start Java processes frequently that don’t have to process any changes most of the time.) In PostgreSQL, we can use triggers for updating data in other tables, now even in the MySQL database.
PostgreSQL 9.1 was the first release with Foreign Data Wrappers functionality. With 9.3, even writing into foreign databases is supported. In 9.4 there is a FDW module for accessing other PostgreSQL servers in the Contrib area. Modules for accessing other database types (even NoSQL and Hadoop!) available.
(Linked server functionality has been available in many database systems for a long time. PostgreSQL had „dblink“. However, linked servers usually had to be of the same type.)
There is a FDW module for MySQL from EnterpriseDB. Currently we need to compile it ourselves, as there are no binary packages in the usual repositories. But it’s not hard.
This is the installation on a Debian system:
git clone https://github.com/EnterpriseDB/mysql_fdw.git
apt-get install make gcc libmysqlclient-dev postgresql-server-dev-9.4
cd mysql_fdw
make USE_PGXS=1
make USE_PGXS=1 install
After this, the module is compiled and registered as a PostgreSQL extension. The rest of the procedure has to be executed (with database superuser rights) in SQL:
CREATE EXTENSION mysql_fdw;
CREATE SERVER mysql_server FOREIGN DATA WRAPPER mysql_fdw
OPTIONS (host '127.0.0.1', port '3306');
CREATE USER MAPPING FOR username SERVER mysql_server
OPTIONS (username 'myuser', password 'mypassword');
CREATE FOREIGN TABLE mysqltable (
-- Fields of the MySQL table, including their type
)
SERVER mysql_server
OPTIONS (dbname='databasename', table_name='OriginalTableName');
The result of this script is a foreign table „mysqltable“ in the PostgreSQL database. This table can be used like any normal table, you can read and write it.
CREATE EXTENSION registers the compiled module in the current database. (When using multiple databases on a server, CREATE EXTENSION must be executed in each database that will contain foreign tables.)
CREATE SERVER creates the link to the foreign database server and defines connection parameters.
CREATE USER MAPPING is necessary to link a PostgreSQL user to a user in the foreign database. Multiple mappings can be created for different users.
CREATE FOREIGN TABLE defines the foreign table and its name in the foreign database. The field types must exist in PostgreSQL. It is possible to define constraints like NOT NULL or give default values on the PostgreSQL side.
Foreign tables open entire new worlds of possibilities for data integration. Master data don’t need to be copied to multiple databases: other databases can work directly on the original which is always current. Data integration processes run in the database, without a separate ETL software. It’ll be interesting to explore further ideas and usage scenarios.
In Studio wurden die unterstützenden Vorschläge für neue User weiter verbessert. Früher hat Studio nur Operatoren vorgeschlagen, die zu den aktuellen passen; jetzt zeigt es auch an, welche Einstellungen häufig verwendet werden. Außerdem wurde der Excel-Import wesentlich beschleunigt, indem die relevanten Teile neu implementiert wurden, statt wie bisher eine Library zu verwenden.
Am Server debütieren HTML5-Diagramme und -Karten, auf die ich mich besonders freue. Die HTML5-Diagramme sollen mittelfristig die bisherigen Flash-basierten Diagrammformate ablösen, die ja unter anderem die mobile Nutzung der Dashboards verhindern.
Ein lang erwartetes Feature am Server war die Versionierung der Prozesse. Dies ist endlich möglich.
Für Big-Data-Umgebungen wurden weitere Verbesserungen eingeführt, unter anderem Kerberos-Authentifizierung in Hadoop-Clustern und die Unterstützung von Apache Spark für eine schnellere Verarbeitung vieler Aufgaben.
RapidMiner kann auf der Homepage heruntergeladen werden.
Pentaho BI Platform 5.3
Die Neuerungen in der Pentaho-Plattform sind einerseits dem Bereich Big Data zuzuordnen, andererseits inkrementelle Verbesserungen und Bugfixes. Auch ein Patch von mir für die Unterstützung von Sequenzen in Netezza-Datenbanken ist in Data Integration aufgenommen worden.
Pentaho Community Edition ist auf der Community-Seite herunterzuladen.
A week of updates
Two of the most popular tools of data scientists – which I work with most frequently – received updates in this week.
RapidMiner Studio 6.3 and Server 2.3
Studio got improvements for new users in the operator recommendation functionality. In earlier versions, it recommended only useful or frequently used operators matching the current process. Now, also sensible settings for the operators are shown. Also, import of Excel files was improved by implementing the needed functionality in RapidMiner instead of using an existing library.
On the server, HTML5 charts and maps are available for the first time. They will replace the older Flash based charts which were problematic in mobile and open source environments.
A long-awaited feature, versioning of processes on the server, is finally available.
There are further improvements for Big Data environments: Kerberos authentication for Hadoop clusters and support for Apache Spark for faster processing of many workloads.
RapidMiner is available for download on the homepage.
Pentaho BI Platform 5.3
The news in this release are mainly in the Big Data area and also incremental improvements as well as bugfixes. I also contributed a patch for sequence support in Netezza databases that went into Data Integration.
Pentaho Community Edition is available on the Community page.
Vor kurzem wurde ich gefragt, wie aufwändig es ist, das Ergebnis eines ETL-Jobs (also aus Pentaho Data Integration) im BA Server auf einem Dashboard auszugeben. Es ist gar nicht kompliziert und geht sehr schnell.
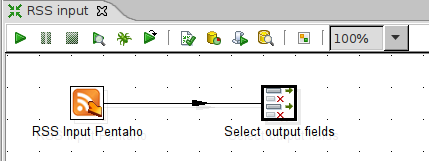
Als erstes erstellen wir eine Transformation und merken uns den Namen des Schrittes, dessen Ergebnis im BA Server ausgegeben werden soll. In diesem Beispiel lese ich den RSS-Feed von pentaho.com aus und selektiere daraus die Spalten Titel, Text und Datum.
Beispiel-Transformation
Diese Transformation muß dann auf den Server geladen werden. Wenn man in Kettle ohne Repository oder mit einem Datei-Repository arbeitet, ist die Datei schon vorhanden; aus einem Datenbank-Repository müßte man sie exportieren (File/Export/To XML).
Die .ktr-Datei wird dann im BA Server unter Browse Files ins gewünschte Verzeichnis raufgeladen (Upload…).
Danach geht’s ans Erstellen des Dashboards. Im Hauptmenü Create New, dann CDE Dashboard. (Wenn dieser Menüpunkt nicht erscheint, muß man im Marketplace „Community Dashboard Editor“ installieren und den Server neu starten.)
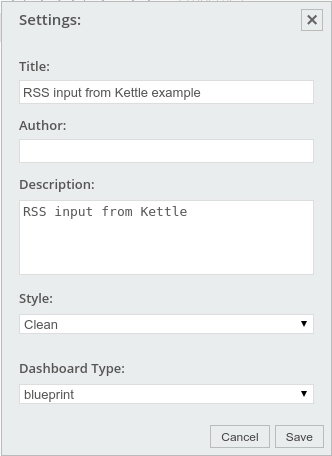
Der erste Weg führt zu den Einstellungen des Dashboards:
Dashboard-Einstellungen
Interessant hier ist die Auswahl des Dashboard-Typs: blueprint oder bootstrap. Blueprint ist (noch?) Standard, aber viele neue Dashboards entstehen mit dem moderneren Bootstrap-Framework. Hier arbeiten wir mit dem Standard, blueprint.
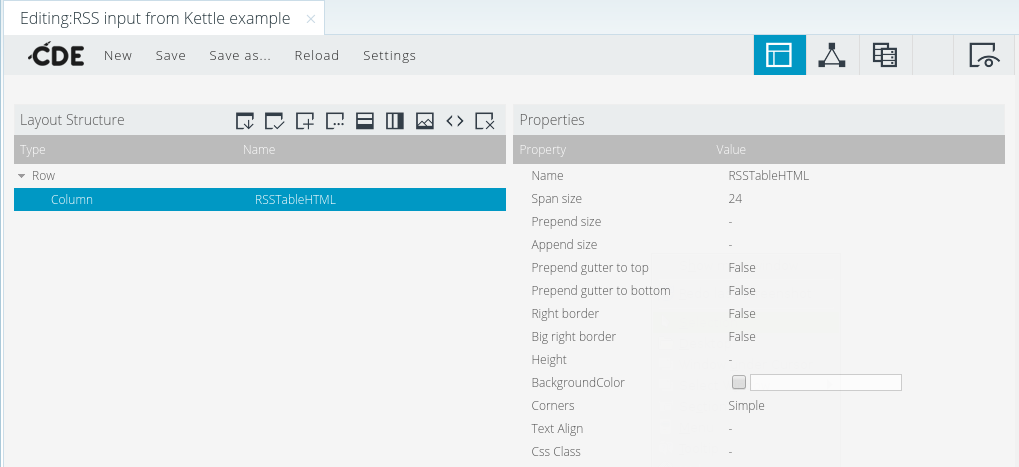
In diesem Beispiel brauchen wir keine komplexe Dashboard-Struktur (die auch möglich wäre). Deswegen fügen wir nur eine Zeile und innerhalb der Zeile eine Spalte ein. Wir geben der Zeile einen Namen (RSSTableHTML) und stellen Span size auf 24, weil bei Blueprint die ganze Breite auf 24 Spalten aufgeteilt ist.
Dashboard-Struktur
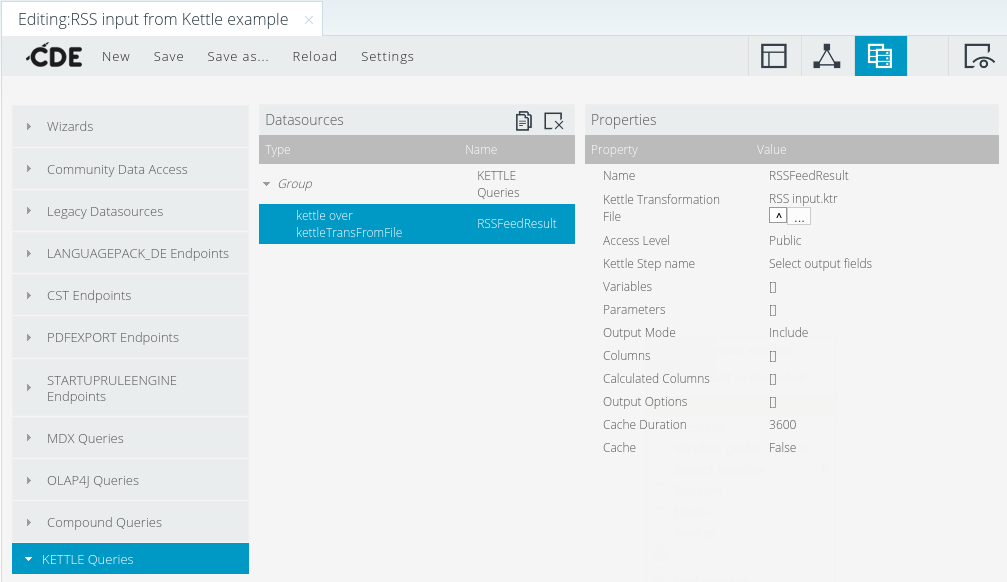
Als nächstes kommt die Datenquelle. Dazu wählen wir unter Datenquellen aus den „KETTLE Queries“ den Eintrag „kettle over kettleTransFromFile“ und stellen die Eigenschaften ein.
Name: RSSFeedResult
Kettle Transformation File: (die hochgeladene Datei wählen)
Kettle Step name: Der Schritt, dessen Ergebnis ausgegeben werden soll
Wir können Cache=True belassen, um das Ergebnis für eine Stunde (3600 Sekunden) zu cachen.
Eigenschaften der Kettle-Datenquelle
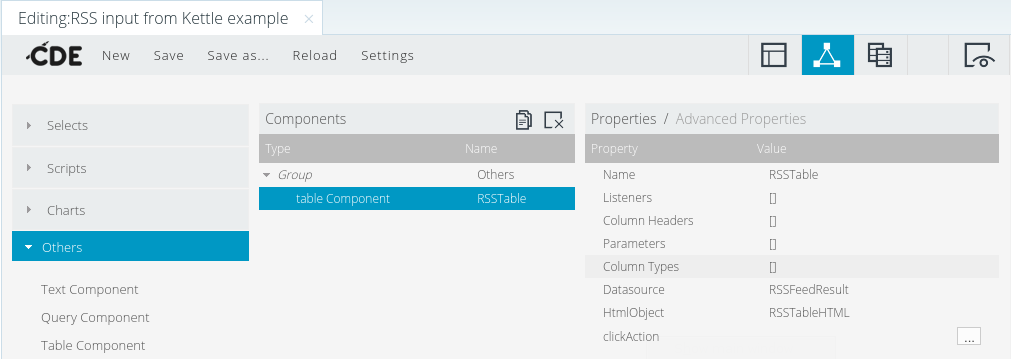
Jetzt bleibt nur mehr die Tabelle. Unter Komponenten wählen wir Others und Table Component. Wir benennen die Komponente (RSSTable), wählen die Datenquelle (RSSFeedResult) und das HTML-Objekt, in dem die Tabelle angezeigt wird (RSSTableHTML). Fertig!
Tabellenkomponente
Wer mit dem Aussehen der Tabelle nicht zufrieden ist, kann unter Advanced Properties noch einiges umstellen und z. B. Style auf Classic umstellen.
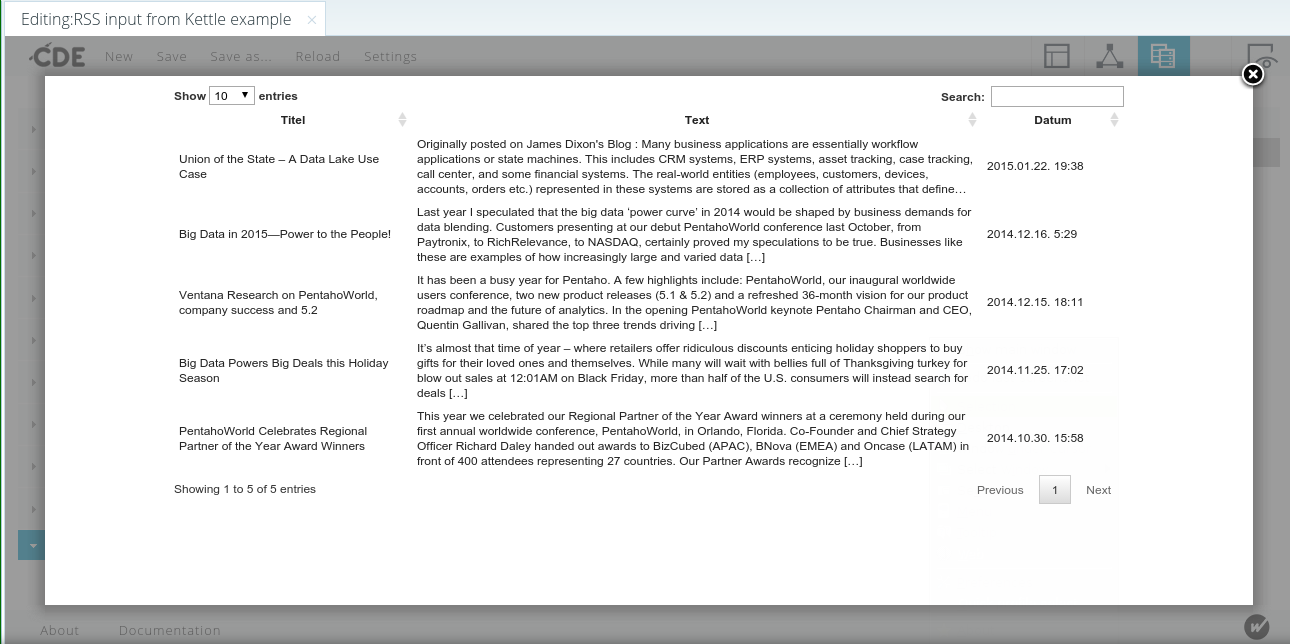
Das Ergebnis der Bemühungen ist eine schöne Tabelle mit den Inhalten des RSS-Feeds.
Dashboard-Vorschau
Natürlich können die Kettle-Transformationen und die Dashboards beliebig komplex werden. Es ist nur zu beachten, daß der Datenerfassungsprozess nicht zu lang dauert, sonst warten die Benutzer des Dashboards zu lange.