Ich hatte die Aufgabe, Daten aus einem anderen Prozess im RapidMiner-Repository auszulesen. Interessant war in diesem Fall der konkrete Wert eines Makros im Prozesskontext. Das ist eine Konfigurationseinstellung, die nur dort festgelegt wird, aber auch anderswo nötig ist.
Mit Bordmitteln kommt man nicht weiter: Loop Repository, Retrieve, Open File weigern sich alle, einen Prozess aus dem Repository zu öffnen. Auch in den Extensions „Converters“ und „Operator Toolbox“ gibt es nichts dazu.
Aber wie so oft bei RapidMiner hilft ein kurzes Groovy-Skript, das man im eingebauten „Execute Script“-Operator ausführt.
import com.rapidminer.repository.RepositoryLocation;
import com.rapidminer.RepositoryProcessLocation;
//Aktueller Pfad im Repository
parentLoc = operator.getProcess().getRepositoryLocation().parent();
//Repository-Eintrag relativ zum aktuellen Pfad
loc = new RepositoryLocation(parentLoc, "Example process");
//Der auszulesende Prozess als XML-String
processCode = new RepositoryProcessLocation(loc).getRawXML();
//Den Code als Macro ausgeben
operator.getProcess().getMacroHandler().addMacro("processXML", processCode);
Nach der Ausführung steht dann im Macro „processXML“ der XML-Code des ausgelesenen Prozesses. Daraus können wir dann mit RapidMiner-Bordmitteln die gewünschte Information rausholen.
In diesem Beispiel lesen wir zwei Dinge aus:
Den Wert des Makros „exampleMacro“ im Prozesskontext
Den Parameter „number_examples“ im Operator „Generate Data“
Mit Create Document und Write Document aus der Text-Processing-Erweiterung können wir den Wert des Makros in ein Document-Objekt umwandeln und in eine Datei schreiben. Das hilft bei der Erfassung der Daten mit dem Read-XML-Wizard, oder bei der Entwicklung der XPath-Ausdrücke mit einem XPath-Tester.
Man findet mit etwas Ausprobieren recht leicht die notwendigen XPath-Ausdrücke. Für den Kontext-Macro:
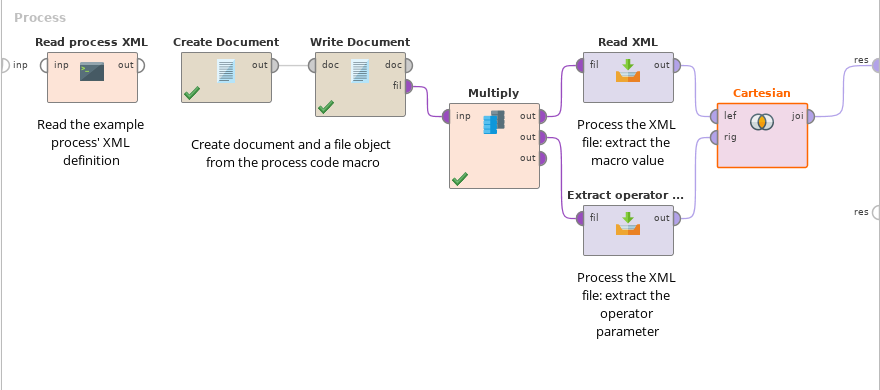
Diese Ausdrücke erscheinen etwas komplex, aber wenn man XPath erstmal gelernt hat, doch recht logisch. Natürlich könnte man die richtigen Pfade in Read XML grafisch auswählen, über die Kontext-Makros bzw. Operator-Parameter iterieren, und dann mit Filter Examples die richtigen Daten auslesen. Das ist Geschmackssache. Der ganze Prozess kann so aussehen:
Beispielprozess zum Auslesen der Metadaten eines anderen Prozesses in RapidMiner Studio
Grundsätzlich funktioniert der Prozess auch auf dem Server. Ich hatte bei der Implementierung eines Webservices jedoch eine Eigenart entdeckt: Bei der direkten Ausführung des Prozesses gab es einen Fehler bei der Ermittlung des aktuellen Repository-Pfades. Das konnte ich jedoch umgehen, indem ich diesen Prozess einfach in einen anderen eingebettet und mit Execute Process ausgeführt habe.
Der Beispielprozess kann hier heruntergeladen werden.
Accessing the process definition in RapidMiner
I got a somewhat special task: We needed some data from another RapidMiner process in the repository, namely the value of a process context macro. This macro is a configuration value, it needs to be defined in one place, but is being used in others.
The built in methods don’t help: Loop Repository, Retrieve, Open File all detect the object type and refuse to open the process. The useful extensions Converters and Operator Toolbox also don’t contain anything for this task.
But — as it is so often the case in RapidMiner — a short Groovy script helps. It is executed in an Execute Script operator.
import com.rapidminer.repository.RepositoryLocation;
import com.rapidminer.RepositoryProcessLocation;
//Current repository path
parentLoc = operator.getProcess().getRepositoryLocation().parent();
//Other repository entry, relative to the current path
loc = new RepositoryLocation(parentLoc, "Example process");
//Process to read as XML
processCode = new RepositoryProcessLocation(loc).getRawXML();
//Add a macro with the process XML
operator.getProcess().getMacroHandler().addMacro("processXML", processCode);
After executing this script, the macro „processXML“ contains the other process in its XML representation. Now we can use standard RapidMiner functionality to extract the necessary information.
Here we extract two items from the process definition:
The value of the macro „exampleMacro“ in the process context
The parameter value for „number_examples“ in the operator „Generate Data“
Create Document and Write Document in the Text Processing extension are being used to create a Document object from the macro value and write it into a file. With this, we can use the wizard in Read XML, and develop XPath expressions in an XPath tester.
With some experimenting we easily find the necessary XPath expressions. To get the context macro with the specified name:
These expressions seem to be a bit complex, but it’s really basic XPath. If you prefer to work more code-free, you can select the containing paths in the Read XML wizard and then use Filter Examples to get the data you prefer. This is how the entire process could look like:
Example process to read metadata from another process in RapidMiner Studio
The same process works on the server. I found a small glitch when implementing it as a web service: When accessing the process directly, it throws an error when trying to determine the current repository path. But this can be easily fixed by calling the process from another using Execute Process.
The example process is available for download here.
Seit der Version 7.2 ist der RapidMiner Server in einer eingeschränkten Version frei erhältlich, und es lassen sich sehr nützliche Dinge damit machen.
Eine Kernfunktion ist das geplante Ausführen von Prozessen. Das passiert mit Hilfe von Cron-Ausdrücken, wobei die Implementierung in RM Server die Cron-Syntax vorne um ein Sekunden-Feld erweitert. Das erhöht natürlich die Flexibilität, aber birgt eine Gefahr in sich: wenn man nicht aufpaßt, legt man ganz schnell einen Cron-Job an, der jede Sekunde einen Prozess startet. Das kann auch den besten Server schnell in die Knie zwingen.
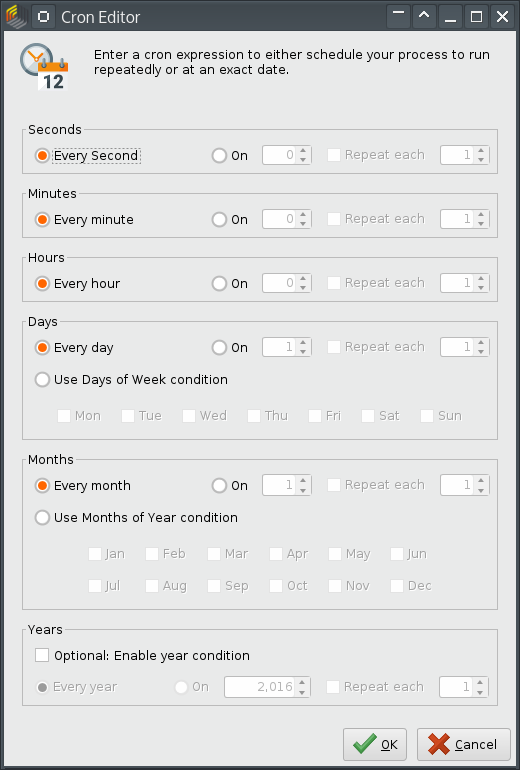
Leider ist die Benutzeroberfläche so gestaltet, daß die Standardeinstellungen genau dieses Problem verursachen:
Cron Editor in RapidMiner Studio mit den Standardeinstellungen
Wer intensiv an einem Server arbeitet, wird vielleicht früher oder später die Standardeinstellungen übernehmen. Oder es passiert jemandem in einem Training dieser Fehler. Glücklicherweise gibt es einen Weg, die Datenbank gegen diese Cron-Jobs abzusichern.
Mein RapidMiner Server verwendet eine PostgreSQL-Datenbank im Hintergrund. Die Tabelle qrtz_cron_triggers enthält die definierten Cron-Jobs. Es ist möglich, einen Trigger auf diese Tabelle zu legen, der unerwünschte Eingaben ablehnt oder, noch eleganter, korrigiert.
In PostgreSQL bestehen Trigger aus zwei Teilen: einer Triggerfunktion und dem eigentlichen Trigger. (Dadurch läßt sich eine Funktion für mehrere ähnliche Trigger verwenden, man muß sie nicht jedes Mal neu schreiben.)
Meine Triggerfunktion schaut so aus:
create or replace function check_second_cron() returns trigger
as $func$
begin
new.cron_expression = regexp_replace(new.cron_expression,
'^\s*(\*|\d+/\d)\s',
'0 ');
return new;
end;
$func$
language plpgsql;
Die Funktion ersetzt im hereinkommenden Cron-Ausdruck unerwünschte Sekundenangaben gegen 0. Eine unerwünschte Angabe ist * (jede Sekunde), die andere hat die Form X/Y (beginnend bei der Sekunde X, alle Y Sekunden). Hier vermeiden wir einstellige Sekundenangaben. Damit kann man einen Prozess alle 10 Sekunden oder seltener laufen lassen, aber nicht häufiger; das reduziert die Gefahr schon wesentlich.
Der reguläre Ausdruck schaut komplex aus, ist aber nicht so schlimm:
^\s* – Am Anfang darf Whitespace (Space oder Tabulator) vorkommen
(\*|\d+/\d) – Entweder ein Stern ODER Ziffer(n) gefolgt von einer Ziffer
\s – Wieder Whitespace
Der Trigger wird dann auf die Tabelle angewendet, und zwar sowohl bei Insert als auch bei Update, und auch nur, wenn der Cron-Ausdruck den unerwünschten Inhalt hat:
drop trigger if exists prevent_second_cron on qrtz_cron_triggers;
create trigger prevent_second_cron
before insert or update
on qrtz_cron_triggers
for each row
when (new.cron_expression ~ '^\s*(\*|\d+/\d)\s')
execute procedure check_second_cron();
Damit wurde der Server gegen die unabsichtliche oder bösartige Eingabe von zu häufig ausgeführten Cron-Prozessen abgesichert. (Natürlich könnte ein Angreifer auch anders viele Prozesse gleichzeitig starten; dagegen helfen nur Queues.)
Securing Cron in RapidMiner Server
A slightly limited version of RapidMiner Server is freely available since release 7.2. It is a very useful piece of software.
Scheduled process execution is a core functionality. The execution time and frequency are specified using Cron expressions; however, the implementation in RM Server extends the usual Cron syntax by a leading Seconds field. This gives us more flexibility but is also dangerous: If we aren’t careful, we can easily schedule a process to run every second. This can cause a huge usage even on the fastest server.
Unfortunately, the default settings in the user interface expose exactly this problem:
Cron Editor in RapidMiner Studio with default settings
People working a lot on a server will probably accept the default values, or someone in a training makes a mistake. Fortunately, there’s a way to secure the database against this kind of Cron schedule.
My RapidMiner Server uses a PostgreSQL backend database. The table qrtz_cron_triggers contains the defined Cron jobs. It is easy to create a trigger on this table that rejects undesired input, or fixes it, which I consider more elegant.
Triggers consist of two parts in PostgreSQL: a trigger function and the actual trigger. (This allows us to use the same function in many triggers instead of writing it many times.)
This is my trigger function:
create or replace function check_second_cron() returns trigger
as $func$
begin
new.cron_expression = regexp_replace(new.cron_expression,
'^\s*(\*|\d+/\d)\s',
'0 ');
return new;
end;
$func$
language plpgsql;
The function replaces unwanted specification of seconds by zero. One kind of unwanted entry is * (every second), the other variant has the form X/Y (start at X seconds, repeat every Y seconds). Here we deny one-digit second entries. This allows us to schedule a process every 10 or more seconds, but not more frequently. This reduces the problem by a large margin.
The regular expression seems complex but it’s not too bad:
^\s* – The beginning of the expression can contain whitespace
(\*|\d+/\d) – A star OR digit(s) followed by / and one digit
\s – Whitespace again
The trigger is placed on the table both for Insert and Update and is executed when the expression has unwanted contents:
drop trigger if exists prevent_second_cron on qrtz_cron_triggers;
create trigger prevent_second_cron
before insert or update
on qrtz_cron_triggers
for each row
when (new.cron_expression ~ '^\s*(\*|\d+/\d)\s')
execute procedure check_second_cron();
Thus the server was secured against unintentional or malicious creation of Cron processes that run too often. (An attacker could start many processes at a time with other means, of course. This can be avoided with Queues.)
Nach der Artikelserie über GIS in RapidMiner Studio (1, 2, 3, 4) geht es nun darum, wie die erhaltenen Ergebnisse visualisiert werden können. In Studio sind die Möglichkeiten dafür ja ziemlich eingeschränkt: Punkt-Daten können noch halbwegs als Scatterplots angezeigt werden, aber für Linien und Flächen gibt es keine guten Methoden.
RapidMiner Server bietet aber mit den Webapps die Möglichkeit einer flexiblen Visualisierung durch die Einbindung von JavaScript.
Einbindung von GeoTools
Für die nachfolgende Vorgehensweise ist es nicht notwendig, den Server ähnlich wie Studio mit Geo-Libraries auszustatten. Wenn man jedoch die gleichen GIS-Funktionen wie in Studio verwenden will, kann es sinnvoll sein.
Ausgehend vom eingerichteten geoscript-Verzeichnis wie im ersten Teil der Anleitung werden die Jar-Bibliotheken aus diesem Verzeichnis in die EAR-Datei des Servers kopiert. Man braucht dazu ein Zip-Werkzeug, ich habe den Midnight Commander verwendet.
RapidMiner Server beenden
rapidminer-server/standalone/deployments/rapidminer-server-X.Y.Z.ear zur Sicherheit anderswo hinkopieren
Aus dem lib/-Verzeichnis die alte groovy-X.jar löschen und die neue aus der Studio-Installation hineinkopieren
Alle Jar-Dateien aus dem geoscript-Ordner der Studio-Installation auch in lib/ kopieren. Wenn eine Datei schon vorhanden ist, muß sie nicht überschrieben werden.
RapidMiner Server starten.
Danach sollten alle Prozesse mit GIS-Verarbeitung aus Studio auch am Server funktionieren.
Visualisierung in Webapps
Meine Wahl fiel auf die Leaflet-Library, da sie Open Source und gut dokumentiert ist. Da wir in RapidMiner keinen eigenen GIS-Datentyp haben und die bisherigen Prozesse die Geodaten als WKT (Well Known Text) verarbeiten, brauchen wir noch die Mapbox-Omnivore-Library. Diese konvertiert WKT-Daten in GeoJSON, das bevorzugte Format von Leaflet.
Vor der Erstellung des Webapps bauen wir einen Prozess in Studio, der die gewünschten Daten ausgibt. Ein Beispielprozess könnte vom Wiener Open-Data-Server die Bezirksgrenzen als CSV und Bevölkerungsstatistiken holen. Die Bezirke werden über ein gemeinsames Feld (NUTS-Id) verknüpft. Der Output des Prozesses ist eine Tabelle mit den Geodaten des Bezirks, ihrer Fläche, der Gesamtbevölkerung und der Bevölkerungsdichte. Für die Bevölkerungsdichte errechnen wir mit Generate Attributes die Anzahl der Personen pro Quadratkilometer und klassifizieren sie, indem wir verschiedenen Wertbereichen HTML-Farben in der #AABBCC-Notation zuweisen. Hier ist die eigene Kreativität gefragt.
Der Prozess wird auf den Server gelegt. Unter Processes/Services legen wir eine neue Eintragung an und nennen sie z. B. ViennaDistrictPopDensitySvc. Wir wählen als Datenquelle den vorhin angelegten Prozess und als Output Format JSON. Es ist sinnvoll, dieses Webservice als anonym/öffentlich aufzusetzen, um zusätzliche Paßworteingaben zu vermeiden.
In der neuen Webapplikation erzeugen wir eine Komponente vom Typ Text, und schalten „Use graphical editor“ ab. Danach geben wir den HTML- und JavaScript-Code ein.
Dieser Teil holt die Leaflet- und Omnivore-Komponenten und erzeugt ein Objekt, in das die Karte eingefügt werden kann. Im CSS wird die Höhe in Pixeln angegeben (z. B. 650px).
Danach starten wir mit <script language="JavaScript"> einen JavaScript-Block, der am Ende mit </script> geschlossen wird.
Hier erzeugen wir das Kartenobjekt mit einer OpenStreetMap-Hintergrundkarte. Die Initialisierungsparameter sind Längen- und Breitengrad der anfänglichen Position der Karte, die Zahl dahinter (11 in diesem Beispiel) die Zoom-Stufe.
Es gibt viele Tile-Server, man sollte die Nutzungsbedingungen prüfen und die Herkunftsangabe (attribution) entsprechend anpassen.
Daten des RapidMiner-Prozesses holen
var Httpreq = new XMLHttpRequest();
Httpreq.open("GET","/api/rest/public/process/ViennaDistrictPopDensitySvc?",false);
Httpreq.send(null);
var mapdata = JSON.parse(Httpreq.responseText);
Dieser Block holt vom lokalen (oder auch einem beliebigen anderen) RapidMiner Server die Daten des Prozesses im JSON-Format und legt sie im mapdata-Objekt ab. Die URL des Webservice kann hier angepaßt werden.
Anzeige der Geo-Objekte
for (i = 0; i < mapdata.length; i++) {
var district = omnivore.wkt.parse(mapdata[i].SHAPE);
district.addTo(map)
.bindPopup(mapdata[i].NAME + "
Population density: " + mapdata[i].POP_DENSITY)
.setStyle({color: mapdata[i].densityColor, weight: 2, fillOpacity: 0.3});
}
Hier verarbeiten wir die Ergebnisse des Prozesses in einer Schleife. Aus jeder Zeile wird die Form des Bezirks (Attribut SHAPE in den Beispieldaten) mit Hilfe von Omnivore konvertiert, und als neues Objekt zur Karte hinzugefügt. Mit .setStyle(...) ordnen wir die im Prozess erzeugte Farbabstufung (im Beispiel das densityColor-Attribut) zu. Als zusätzliche Information erzeugen wir mit .bindPopup(...) noch ein Popup-Fenster, das beim Klick auf einen Bezirk angezeigt wird und zusätzliche Informationen enthält.
Linien-Daten werden ganz ähnlich angezeigt und verarbeitet. Bei Punkt-Daten können verschiedene Marker definiert werden, bei Leaflet gibt es die Anleitung dazu.
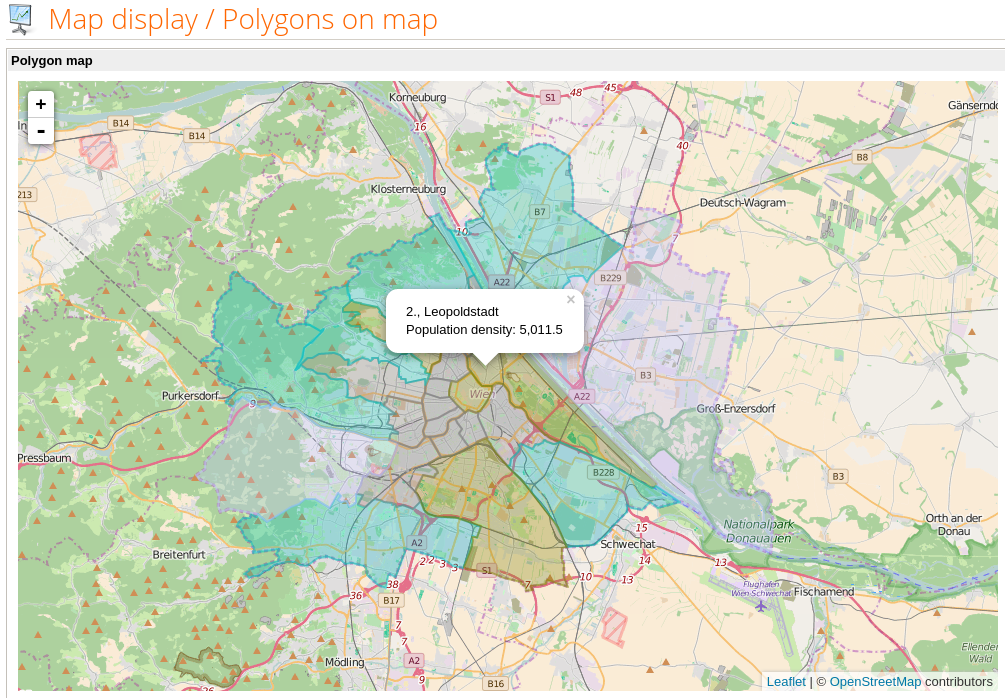
Damit ist das Ziel erreicht: RapidMiner Server zeigt eine Karte an, deren Daten (Punkte, Linien oder Flächen) in einen RapidMiner-Prozess verarbeitet wurden.
Bevölkerungsdichte pro Bezirk in Wien (Daten: Open Data Wien)
After the series of blog posts about GIS in RapidMiner Studio (1, 2, 3, 4) we’d probably like to visualize our results. The mechanisms in Studio are quite limited: we can create scatter plots from point data but there is no good method for displaying lines and areas.
However, RapidMiner Server offers webapps and powerful visualization using JavaScript.
Using GeoScript in processes
For displaying geographic data it’s not necessary to set up the server with the GeoScript libraries. However, if you want to execute the GIS processes like in studio, it can be a good idea to do so.
Start with the geoscript directory set up in the first part. You’ll need a Zip utility; I used Midnight Commander.
Stop RapidMiner Server
Make a backup copy of rapidminer-server/standalone/deployments/rapidminer-server-X.Y.Z.ear somewhere else
Delete the old groovy-X.jar from the lib/ directory and put in the new one from the Studio installation
Copy all jar files from the geoscript directory of the Studio installation to lib/. Existing files don’t need to be overwritten.
Start RapidMiner Server.
After this process, all your Studio GIS processes should work in the Server.
Map display in webapps
I chose the Leaflet library, as it is open source and well documented. There is no special GIS data type in RapidMiner and the processes in the tutorials used WKT (Well Known Text) until now, so we’ll also need the Mapbox Omnivore library. This converts WKT data to GeoJSON which Leaflet prefers.
Before starting with the web app, we need to build a process in Studio for creating the data. An example process could use the district boundaries as CSV and the population statistics from the Vienna Open Data server. It joins the districts using a common attribute (NUTS id). The output of the process is a table with the district boundaries, their area, the total population and the population density. We also use Generate Attributes to classify the population density with HTML colors (#AABBCC notation). You can get creative here and use the entire functionality of RapidMiner.
The process is saved on the server. We create a new entry in Processes/Services and call it for example ViennaDistrictPopDensitySvc. The data source is the process created before, the output format is JSON. It is a good idea to set up this web service for public anonymous access.
In a new web app we create a Text component and uncheck the „Use graphical editor“ checkbox to enter HTML and JavaScript code.
This part fetches the Leaflet and Omnivore components and creates a DIV object for the map. We specify the map height in pixels in the CSS block (e. g. 650px).
Then a JavaScript block is started with <script language="JavaScript">. Don’t forget to close the block with </script> at the end.
This creates a map object with an OpenStreetMap background layer. The initialization parameters are latitude and longitude of the initial position, and the zoom level (11 in this example).
There are many tile servers available. Be sure to check the terms of usage and update the attribution appropriately.
Getting data from the RapidMiner process
var Httpreq = new XMLHttpRequest();
Httpreq.open("GET","/api/rest/public/process/ViennaDistrictPopDensitySvc?",false);
Httpreq.send(null);
var mapdata = JSON.parse(Httpreq.responseText);
This part fetches the data in JSON format from the local RapidMiner Server and stores them in the mapdata variable. To refer to another web service, change the URL.
Displaying the objects on the map
for (i = 0; i < mapdata.length; i++) {
var district = omnivore.wkt.parse(mapdata[i].SHAPE);
district.addTo(map)
.bindPopup(mapdata[i].NAME + "
Population density: " + mapdata[i].POP_DENSITY)
.setStyle({color: mapdata[i].densityColor, weight: 2, fillOpacity: 0.3});
}
Here, a loop processes the process results. The Omnivore function converts the district area (SHAPE attribute in the example data) to a new object on the map. We assign the color calculated in the process with .setStyle(...) (densityColor attribute in this example). We also create a popup window with additional information using .bindPopup(...). It will be displayed when the user clicks a district.
Displaying line data is very similar. For displaying point data, you can use different markers. This is described by a Leaflet tutorial.
So we reached our goal: RapidMiner Server displays a map with data (points, lines or areas or even a combination) coming from a RapidMiner process.
Population density by district in Vienna (Data: Open Data Vienna)
In Studio wurden die unterstützenden Vorschläge für neue User weiter verbessert. Früher hat Studio nur Operatoren vorgeschlagen, die zu den aktuellen passen; jetzt zeigt es auch an, welche Einstellungen häufig verwendet werden. Außerdem wurde der Excel-Import wesentlich beschleunigt, indem die relevanten Teile neu implementiert wurden, statt wie bisher eine Library zu verwenden.
Am Server debütieren HTML5-Diagramme und -Karten, auf die ich mich besonders freue. Die HTML5-Diagramme sollen mittelfristig die bisherigen Flash-basierten Diagrammformate ablösen, die ja unter anderem die mobile Nutzung der Dashboards verhindern.
Ein lang erwartetes Feature am Server war die Versionierung der Prozesse. Dies ist endlich möglich.
Für Big-Data-Umgebungen wurden weitere Verbesserungen eingeführt, unter anderem Kerberos-Authentifizierung in Hadoop-Clustern und die Unterstützung von Apache Spark für eine schnellere Verarbeitung vieler Aufgaben.
RapidMiner kann auf der Homepage heruntergeladen werden.
Pentaho BI Platform 5.3
Die Neuerungen in der Pentaho-Plattform sind einerseits dem Bereich Big Data zuzuordnen, andererseits inkrementelle Verbesserungen und Bugfixes. Auch ein Patch von mir für die Unterstützung von Sequenzen in Netezza-Datenbanken ist in Data Integration aufgenommen worden.
Pentaho Community Edition ist auf der Community-Seite herunterzuladen.
A week of updates
Two of the most popular tools of data scientists – which I work with most frequently – received updates in this week.
RapidMiner Studio 6.3 and Server 2.3
Studio got improvements for new users in the operator recommendation functionality. In earlier versions, it recommended only useful or frequently used operators matching the current process. Now, also sensible settings for the operators are shown. Also, import of Excel files was improved by implementing the needed functionality in RapidMiner instead of using an existing library.
On the server, HTML5 charts and maps are available for the first time. They will replace the older Flash based charts which were problematic in mobile and open source environments.
A long-awaited feature, versioning of processes on the server, is finally available.
There are further improvements for Big Data environments: Kerberos authentication for Hadoop clusters and support for Apache Spark for faster processing of many workloads.
RapidMiner is available for download on the homepage.
Pentaho BI Platform 5.3
The news in this release are mainly in the Big Data area and also incremental improvements as well as bugfixes. I also contributed a patch for sequence support in Netezza databases that went into Data Integration.
Pentaho Community Edition is available on the Community page.