(English)
Ich hatte die Aufgabe, Daten aus einem anderen Prozess im RapidMiner-Repository auszulesen. Interessant war in diesem Fall der konkrete Wert eines Makros im Prozesskontext. Das ist eine Konfigurationseinstellung, die nur dort festgelegt wird, aber auch anderswo nötig ist.
Mit Bordmitteln kommt man nicht weiter: Loop Repository, Retrieve, Open File weigern sich alle, einen Prozess aus dem Repository zu öffnen. Auch in den Extensions „Converters“ und „Operator Toolbox“ gibt es nichts dazu.
Aber wie so oft bei RapidMiner hilft ein kurzes Groovy-Skript, das man im eingebauten „Execute Script“-Operator ausführt.
import com.rapidminer.repository.RepositoryLocation;
import com.rapidminer.RepositoryProcessLocation;
//Aktueller Pfad im Repository
parentLoc = operator.getProcess().getRepositoryLocation().parent();
//Repository-Eintrag relativ zum aktuellen Pfad
loc = new RepositoryLocation(parentLoc, "Example process");
//Der auszulesende Prozess als XML-String
processCode = new RepositoryProcessLocation(loc).getRawXML();
//Den Code als Macro ausgeben
operator.getProcess().getMacroHandler().addMacro("processXML", processCode);
Nach der Ausführung steht dann im Macro „processXML“ der XML-Code des ausgelesenen Prozesses. Daraus können wir dann mit RapidMiner-Bordmitteln die gewünschte Information rausholen.
In diesem Beispiel lesen wir zwei Dinge aus:
- Den Wert des Makros „exampleMacro“ im Prozesskontext
- Den Parameter „number_examples“ im Operator „Generate Data“
Mit Create Document und Write Document aus der Text-Processing-Erweiterung können wir den Wert des Makros in ein Document-Objekt umwandeln und in eine Datei schreiben. Das hilft bei der Erfassung der Daten mit dem Read-XML-Wizard, oder bei der Entwicklung der XPath-Ausdrücke mit einem XPath-Tester.
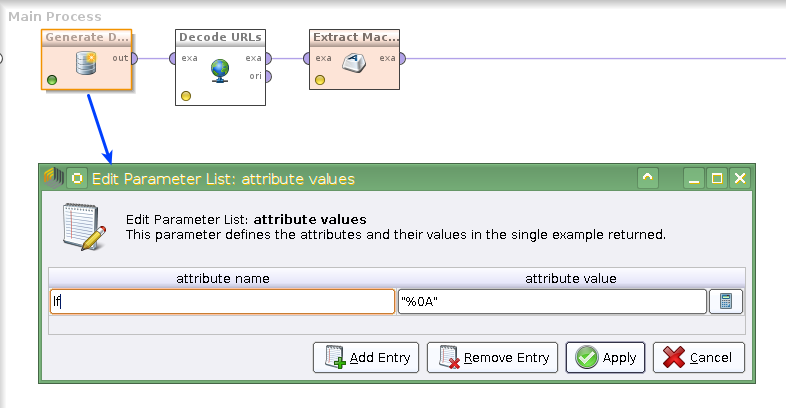
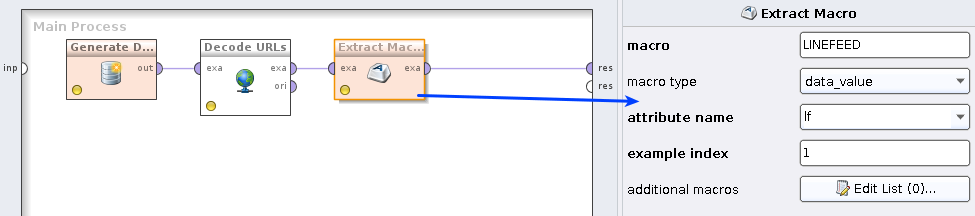
Man findet mit etwas Ausprobieren recht leicht die notwendigen XPath-Ausdrücke. Für den Kontext-Macro:
//context/macros/macro[key/text() = 'exampleMacro']/value
Und für den Parameter des Operators:
//process/operator/process/operator[@name = 'Generate Data']/parameter[@key='number_examples']
Diese Ausdrücke erscheinen etwas komplex, aber wenn man XPath erstmal gelernt hat, doch recht logisch. Natürlich könnte man die richtigen Pfade in Read XML grafisch auswählen, über die Kontext-Makros bzw. Operator-Parameter iterieren, und dann mit Filter Examples die richtigen Daten auslesen. Das ist Geschmackssache. Der ganze Prozess kann so aussehen:
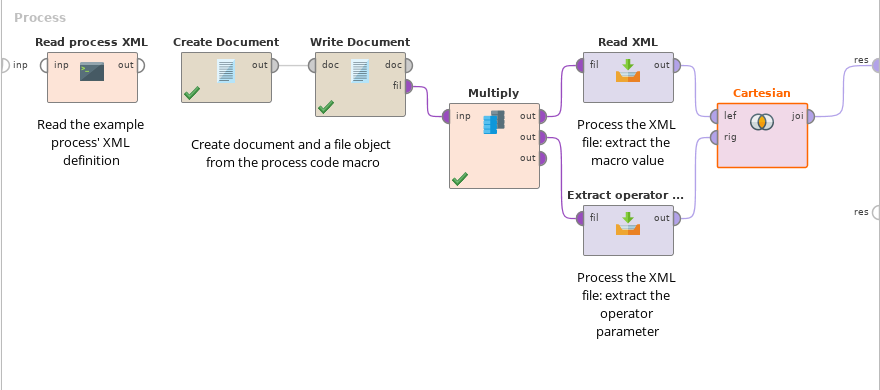
Grundsätzlich funktioniert der Prozess auch auf dem Server. Ich hatte bei der Implementierung eines Webservices jedoch eine Eigenart entdeckt: Bei der direkten Ausführung des Prozesses gab es einen Fehler bei der Ermittlung des aktuellen Repository-Pfades. Das konnte ich jedoch umgehen, indem ich diesen Prozess einfach in einen anderen eingebettet und mit Execute Process ausgeführt habe.
Der Beispielprozess kann hier heruntergeladen werden.
Accessing the process definition in RapidMiner
I got a somewhat special task: We needed some data from another RapidMiner process in the repository, namely the value of a process context macro. This macro is a configuration value, it needs to be defined in one place, but is being used in others.
The built in methods don’t help: Loop Repository, Retrieve, Open File all detect the object type and refuse to open the process. The useful extensions Converters and Operator Toolbox also don’t contain anything for this task.
But — as it is so often the case in RapidMiner — a short Groovy script helps. It is executed in an Execute Script operator.
import com.rapidminer.repository.RepositoryLocation;
import com.rapidminer.RepositoryProcessLocation;
//Current repository path
parentLoc = operator.getProcess().getRepositoryLocation().parent();
//Other repository entry, relative to the current path
loc = new RepositoryLocation(parentLoc, "Example process");
//Process to read as XML
processCode = new RepositoryProcessLocation(loc).getRawXML();
//Add a macro with the process XML
operator.getProcess().getMacroHandler().addMacro("processXML", processCode);
After executing this script, the macro „processXML“ contains the other process in its XML representation. Now we can use standard RapidMiner functionality to extract the necessary information.
Here we extract two items from the process definition:
- The value of the macro „exampleMacro“ in the process context
- The parameter value for „number_examples“ in the operator „Generate Data“
Create Document and Write Document in the Text Processing extension are being used to create a Document object from the macro value and write it into a file. With this, we can use the wizard in Read XML, and develop XPath expressions in an XPath tester.
With some experimenting we easily find the necessary XPath expressions. To get the context macro with the specified name:
//context/macros/macro[key/text() = 'exampleMacro']/value
And the operator parameter:
//process/operator/process/operator[@name = 'Generate Data']/parameter[@key='number_examples']
These expressions seem to be a bit complex, but it’s really basic XPath. If you prefer to work more code-free, you can select the containing paths in the Read XML wizard and then use Filter Examples to get the data you prefer.
This is how the entire process could look like:
The same process works on the server. I found a small glitch when implementing it as a web service: When accessing the process directly, it throws an error when trying to determine the current repository path. But this can be easily fixed by calling the process from another using Execute Process.
The example process is available for download here.